I have a column that came from Excel, that is supposed to contain durations (in hours) - example: 02:00:00 -
It works well if all this durations are less than 24:00 but if one is more than that, it appears in pandas as 1900-01-03 08:00:00 (so datetime)
as a result the datatype is dtype('O').
df = pd.DataFrame({'duration':[datetime.time(2, 0), datetime.time(2, 0),
datetime.datetime(1900, 1, 3, 8, 0),
datetime.datetime(1900, 1, 3, 8, 0),
datetime.datetime(1900, 1, 3, 8, 0),
datetime.datetime(1900, 1, 3, 8, 0),
datetime.datetime(1900, 1, 3, 8, 0),
datetime.datetime(1900, 1, 3, 8, 0), datetime.time(1, 0),
datetime.time(1, 0)]})
# Output
duration
0 02:00:00
1 02:00:00
2 1900-01-03 08:00:00
3 1900-01-03 08:00:00
4 1900-01-03 08:00:00
5 1900-01-03 08:00:00
6 1900-01-03 08:00:00
7 1900-01-03 08:00:00
8 01:00:00
9 01:00:00
But if I try to convert to either time or datetime I always get an error.
TypeError: <class 'datetime.time'> is not convertible to datetime
Today if I don't fix this, all the duration greater than 24:00 are gone.
CodePudding user response:
IIUC, use 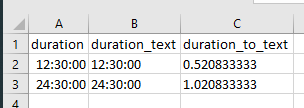
You can download it here.
duration is auto-formatted by Excel, duration_text is what you get if you set the column format to 'text' before you enter the values, duration_to_text is what you get if you change the format to text after Excel auto-formatted the values (first column).
Now you have everything you need after import with pandas:
df = pd.read_excel('path_to_file')
df
duration duration_text duration_to_text
0 12:30:00 12:30:00 0.520833
1 1900-01-01 00:30:00 24:30:00 1.020833
# now you can parse to timedelta:
pd.to_timedelta(df['duration_text'])
0 0 days 12:30:00
1 1 days 00:30:00
Name: duration_text, dtype: timedelta64[ns]
# or
pd.to_timedelta(df['duration_to_text'], unit='d')
0 0 days 12:29:59.999971200 # note the precision issue ;-)
1 1 days 00:29:59.999971200
Name: duration_to_text, dtype: timedelta64[ns]
Another viable option could be to save the Excel file as a csv and import that to a pandas DataFrame. The sample xlsx used above would then look like this for example.
If you have no other option than to re-process in pandas, an option could be to treat datetime.time objects and datetime.datetime objects specifically, e.g.
import datetime
# where you have datetime (incorrect from excel)
m = (isinstance(i, datetime.datetime) for i in df['duration'])
# convert to timedelta where it's possible
df['timedelta'] = pd.to_timedelta(df['duration'].astype(str), errors='coerce')
# where you have datetime, some special treatment is needed...
df.loc[m, 'timedelta'] = df.loc[m, 'duration'].apply(lambda t: pd.Timestamp(str(t)) - pd.Timestamp('1899-12-31'))
df['timedelta']
0 0 days 12:30:00
1 1 days 00:30:00
Name: timedelta, dtype: timedelta64[ns]