I posted this earlier, but I wasn't clear enough, so I will provide a better example in this post. I have a table sitting in bigquery with several columns, I will list the relevant ones.
My goal is to find every possible combination of length 2 for markers.code, and find out the total number of times it's seen and the number of unique devices it's seen on for every day, version, device_type.
Schema:
device_timestamp TIMESTAMP NULLABLE
, mac_address STRING NULLABLE
, version STRING NULLABLE
, device_type STRING NULLABLE
, markers RECORD REPEATED [{code STRING NULLABLE, value STRING NULLABLE}]
Example Data:
2020-01-01 00:00:15, "abcdefgh", "1.01", "android", {"power_off": 2, "buffer_error": 1, "out_of_memory": 1}
2020-01-01 00:00:25, "zasdpqld", "1.01", "android", {"failed_state": 5, "load_error": 2, "power_off": 1, "buffer_error": 1}
2020-01-01 00:53:13, "apelddsa", "1.02", "android", {"black_screen": 1, "kernel_crash": 1, "power_off": 1}
Desired Output Schema:
Schema
date DATE
, version STRING
, device_type STRING
, target_marker STRING
, secondary_marker STRING
, total_seen INT64
, unique_devices INT64
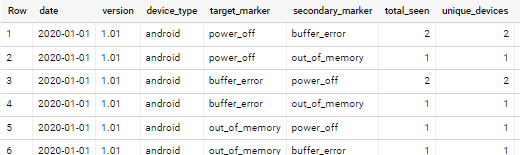
Example Desired Output:
2020-01-01, "1.01", "android", "power_off", "buffer_error", 2, 2
2020-01-01, "1.01", "android", "power_off", "out_of_memory", 1, 1
2020-01-01, "1.01", "android", "buffer_error", "power_off", 2, 2
2020-01-01, "1.01", "android", "buffer_error", "out_of_memory", 1, 1
2020-01-01, "1.01", "android", "out_of_memory", "power_off", 1, 1
2020-01-01, "1.01", "android", "out_of_memory", "buffer_error", 1, 1
2020-01-01, "1.01", "android", "power_off", "failed_state", 1, 1
2020-01-01, "1.01", "android", "power_off", "load_error", 1, 1
2020-01-01, "1.01", "android", "failed_state", "load_error", 1, 1
2020-01-01, "1.01", "android", "failed_state", "power_off", 1, 1
2020-01-01, "1.01", "android", "load_error", "power_off", 1, 1
2020-01-01, "1.02", "android", "black_screen", "kernel_crash", 1, 1
2020-01-01, "1.02", "android", "black_screen", "power_off", 1, 1,
2020-01-01, "1.02", "android", "kernel_crash", "black_screen", 1, 1
2020-01-01, "1.02", "android", "kernel_crash", "power_off", 1, 1
2020-01-01, "1.02", "android", "power_off", "black_screen", 1, 1
2020-01-01, "1.02", "android", "power_off", "kernel_crash", 1, 1
Above is a very easy example to understand the complexity of the problem. With the real dataset, there will be many versions, mac addresses, device types and multiple combinations of two for the marker codes. Total Seen will be a COUNT(*) and unique devices will be a COUNT(DISTINCT mac_address) which will all be grouped by the date, version, device_type, target_marker, secondary_marker.
I hope this makes sense; if any more information is required to complete this problem, please drop a comment.
Thanks!
CodePudding user response:
Consider below
with flatten_data as (
select date(device_timestamp) date, mac_address, version, device_type, code, value, format('%t', t) as entry
from your_table t, t.markers
)
select date, version, device_type,
t1.code as target_marker,
t2.code as secondary_marker,
count(*) as total_seen,
count(distinct t2.mac_address) as unique_devices
from flatten_data t1
join flatten_data t2
using(entry, date, version, device_type)
where t1.code != t2.code
group by date, version, device_type, target_marker, secondary_marker
if applied to sample data in your question - output is (just top few rows shown)