I am working with earthquake data on the 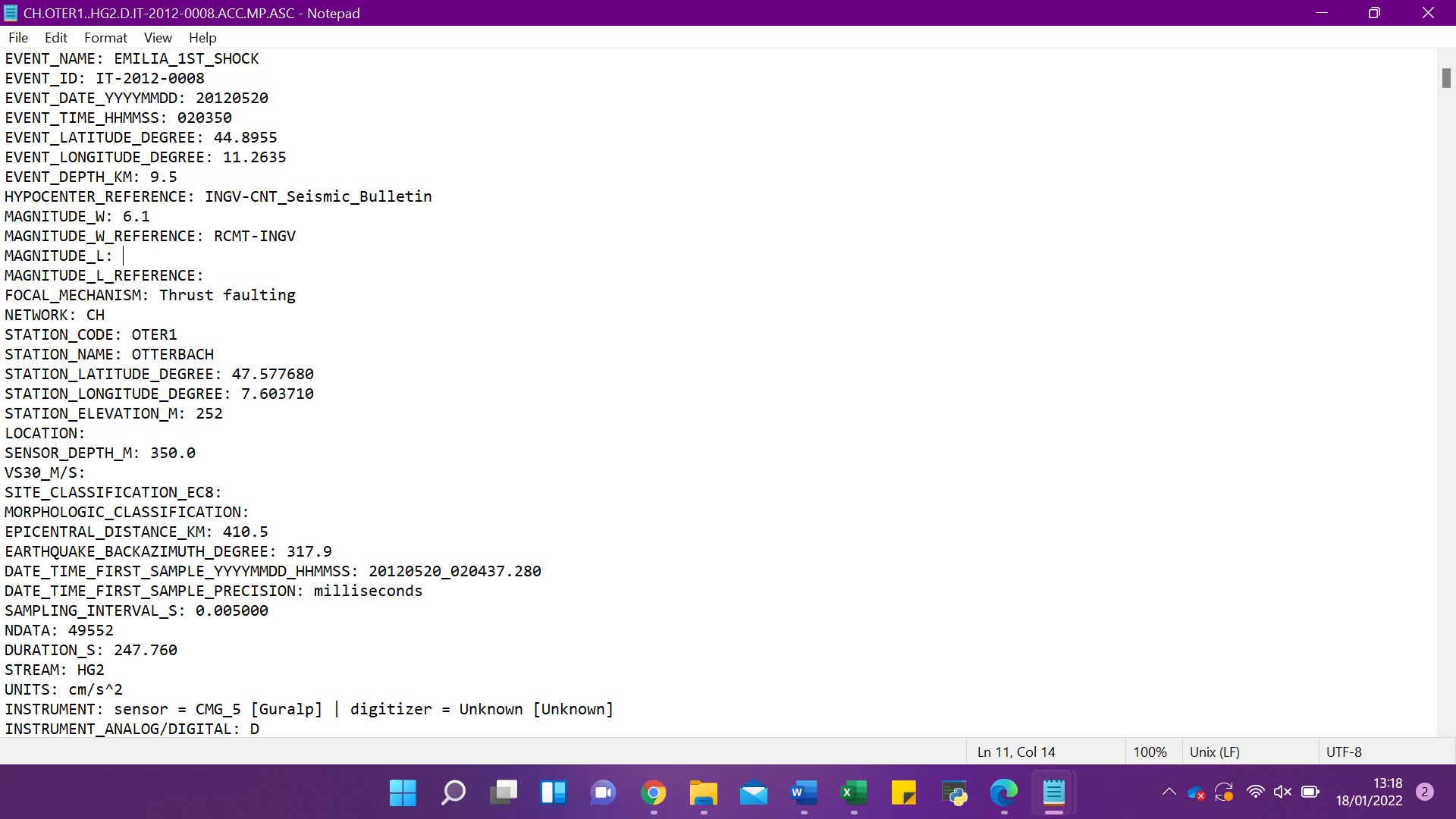
CodePudding user response:
This script could probabaly help! I am assuming all .ASC files are in a folder called "input_files" which is in the same directory as the script! You can change the path to folder where all the .ASC file exist in line number 3 in the below script.
import os
input_dir = "input_files"
output_file = "all_data.txt"
output_lst = []
def process_file(filepath):
interesting_keys = (
'Network',
'Station_Code',
'Station_Name',
'Station_Latitude_Degree',
'Station_Longitude_Degree',
'PGA_CM/S^2'
)
with open(filepath) as fh:
content = fh.readlines()
for line in content:
line = line.strip()
if ":" in line:
key, _ = line.split(":", 1)
if key.strip() in interesting_keys:
output_lst.append(line)
def write_output_data():
if output_lst:
with open(output_file, "w") as fh:
fh.write("\n".join(output_lst))
print("See", output_file)
def process_files():
for filepath in os.listdir(input_dir):
process_file(os.path.join(input_dir, filepath))
write_output_data()
process_files()
CodePudding user response:
this was an interesting one, see script below which downloads all the raw data. I've pulled out the key pieces of data as requested but you may want to look at the raw data yourself as there is so much there.
One thing to note is that the only 'PGA_CM/S^2' data I could find is the value in bold on the "Go" page for each record.
import requests
import pandas as pd
url = 'https://esm-db.eu/esm_next_ws/jsonrpc'
payload = '{"jsonrpc":"2.0","method":"armonia","id":"8","params":{"map":{"_page":"DYNA_X_event_waveform_band_instrument_D","_state":"find","_action_json_rpc_list":"1","_rows_per_page":"10000","internal_event_id":"IT-2012-0008","_operator_internal_event_id":"=","_order_field_0":"epi_dist","_order_direction_0":"asc","_token":"NULLNULLNULLNULL"}}}'
con_len = len(payload)
headers= {
'Accept':'application/json, text/plain, */*',
'Accept-Encoding':'gzip, deflate, br',
'Content-Length':str(con_len),
'Content-Type':'application/x-www-form-urlencoded',
'Host':'esm-db.eu',
'Origin':'https://esm-db.eu',
'Referer':'https://esm-db.eu/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
print('Fetching data...')
data = requests.post(url,headers=headers,data=payload).json()
final = []
for row in data['result']['rows']:
#loads of data, might be worth downloading json (data variable) and seeing what else you want
item = {
'Network':row[39],
'Station_Code':row[22],
'Station_Name':row[46][10],
'Station_Latitude_Degree':row[46][12],
'Station_Longitude_Degree':row[46][3],
'PGA_CM/S^2':row[18], #can only find the value in bold on the "Go" page
'Date':row[24].replace('T',' '),
}
final.append(item)
df = pd.DataFrame(final)
df.to_csv('earthquakedata.csv',index=False)
print('Saved to earthquake.csv')
if you want the whole load of data (it's almost unmanageable in csv) then you could dump it all into csv by changing the last few rows to this:
print('Fetching data...')
data = requests.post(url,headers=headers,data=payload).json()
df = pd.DataFrame(data['result']['rows'])
df.to_csv('earthquakedata_ugly.csv',index=False)
print('Saved to earthquake_ugly.csv')