I have two different data (students performance).
dict1 --- performance for the 1st semester
dict2 --- performance for the 2nd semester
I need to concatenate two df's so that sub-columns for semesters appear in the columns of disciplines.
import pandas as pd
dict1 = {'Students': ['A', 'B', 'C'], 'Dicsipline1': ['a', 'na', 'a'], 'Dicsipline2': ['a', 'na', 'a']}
dict2 = {'Students': ['A', 'B', 'C'], 'Dicsipline1': ['na', 'a', 'a'], 'Dicsipline2': ['a', 'a', 'a']}
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
Desired result like
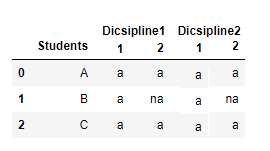
I need to add one level.
CodePudding user response:
Use:
df = pd.concat({'1': df1.set_index('Students'),
'2': df2.set_index('Students')},
axis=1).swaplevel(axis=1).sort_index(axis=1)
Or:
df = pd.concat({'1': df1.set_index('Students'),
'2': df2.set_index('Students')}).unstack(level=0)
Dicsipline1 Dicsipline2
1 2 1 2
Students
A a na a a
B na a na a
C a a a a
Note you can use reset_index() at the end in order to include students in the columns
CodePudding user response:
Do you mean something like this:
linked_dict = {key: [val for val in values dict2[key]] for key, values in dict1.items()}
df = pd.DataFrame(linked_dict)
? If not, please be more specific what do you want to achieve (maybe show the desired result).
Edited: You can do it like this (it is not what you want, but nearby):
dict_1_new = {(key, f'Semester1') if 'Dicsipline' in key else key: value for key, value in dict1.items()}
dict_2_new = {(key, f'Semester2') if 'Dicsipline' in key else key: value for key, value in dict2.items()}
linked_dict = dict_1_new | dict_2_new
df = pd.DataFrame(linked_dict)
CodePudding user response:
The below code will work for your case
import pandas as pd
dict1 = {'Students': ['A', 'B', 'C'], 'Dicsipline1': ['a', 'na', 'a'], 'Dicsipline2': ['a', 'na', 'a']}
dict2 = {'Students': ['A', 'B', 'C'], 'Dicsipline1': ['na', 'a', 'a'], 'Dicsipline2': ['a', 'a', 'a']}
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
df = (pd.concat([df1.set_index('Students'),
df2.set_index('Students')],
axis=1,
keys=['0','1'])
.swaplevel(0,1,axis=1)
.sort_index(axis=1, ascending=[True, False])
)
print (df)
The output will be as:
Dicsipline1 Dicsipline2
1 0 1 0
Students
A na a a a
B a na a na
C a a a a