I'm trying to scrape the parts of the materials on the Zara website. Basically, what I did was:
step#1-open the website in headless mode
step#2-click the "see more" bottom and let the part I'm going to scrape "visible"
step#3-scrape the specific parts that I'm looking for
However, I found I need to run step#2 twice to get the complete text, which is not desirable... Can anyone tell me why this happens? Also, sometimes the code cannot return any text, so I need to wait for seconds and run step#2 again... this is also a problem.
My code is the following:
from selenium import webdriver
import re
driver_path = 'D:/Python/Selenium/chromedriver'
option1 = webdriver.ChromeOptions()
option1.add_argument("--headless")
option1.add_argument("--window-size=1920,1080")
pro_url = 'https://www.zara.com/us/en/longline-down-jacket-limited-edition-p07522271.html?v1=132297981&v2=1988885'
# pro_url = 'https://www.zara.com/us/en/quilted-leather-crossbody-bag-p16774810.html'
# pro_url = 'https://www.zara.com/us/en/slit-straight-leg-pants-p07102160.html?v1=108948748&v2=1989249'
# pro_url = 'https://www.zara.com/us/en/soft-oversized-coat-p03046032.html?v1=157882610&v2=2024686'
# pro_url = 'https://www.zara.com/us/en/plain-sweatshirt-p05584602.html?v1=156787590&v2=1991272'
driver = webdriver.Chrome(chrome_options=option1,executable_path=driver_path)
driver.get(pro_url)
try:
driver.execute_script("arguments[0].click();", driver.find_element_by_xpath('//button[contains(@class,"expandable-text__view-more")]/span'))
except:
driver.execute_script("arguments[0].click();", driver.find_element_by_xpath('//button[contains(@class,"product-detail-extra-detail-expandable__view-more")]/span'))
title_list = driver.find_elements_by_xpath('//span[contains(@class,"structured-component-text zds-body-s")]')
part_ind = [(i-1) for i,s in enumerate(title_list) if re.compile("^[0-9]|^[1-9][0-9]|^(100)").search(s.text)]
part_text = [p.text for p in [title_list[i] for i in part_ind]]
cont_text = [i.text for i in title_list if re.compile("^[0-9]|^[1-9][0-9]|^(100)").search(i.text)]
print(part_text)
print(cont_text)
'''
result for running the first time
['OUTER SHELL', 'LINING']
['100% polyester', '100% polyester']
'''
'''
result for running the second time -- this is what I want:
['OUTER SHELL', 'LINING', 'FILLING']
['100% polyester', '100% polyester', '80% white duck down · 20% feather']
'''
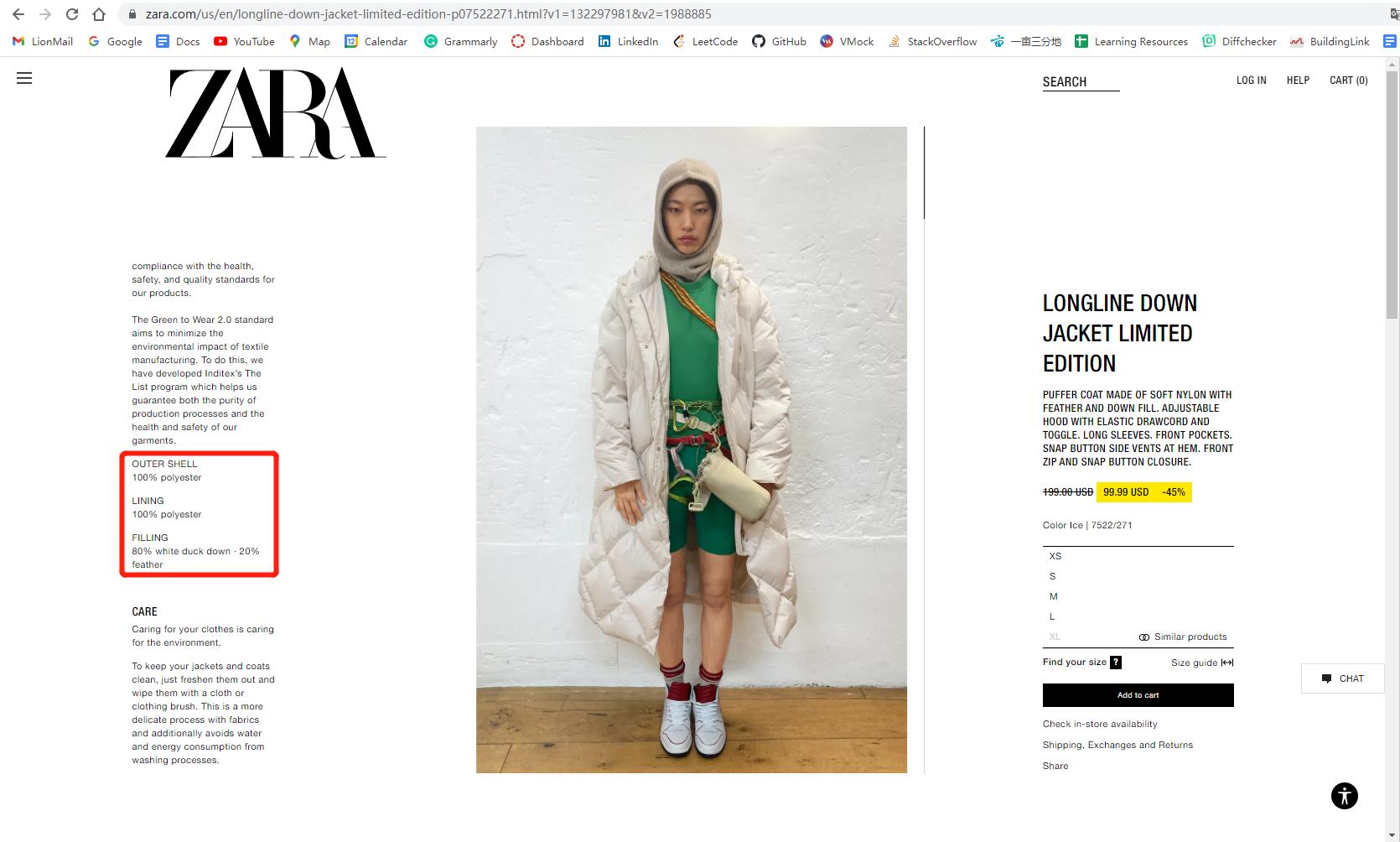
I also paste the website screenshot for reference:
CodePudding user response:
I don't know why your Selenium script isn't working but if you know the product id you can use the backend API to get this information with this endpoint:
https://www.zara.com/us/en/product/{place_product_id_here}/extra-detail
import requests
product_id = 160264609
headers = {
'accept':'*/*',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
url = f'https://www.zara.com/us/en/product/{product_id}/extra-detail?ajax=true'
data = requests.get(url,headers=headers).json()
for info in data[1]['components']:
if info['datatype'] == 'paragraph':
print(info['text']['value'])