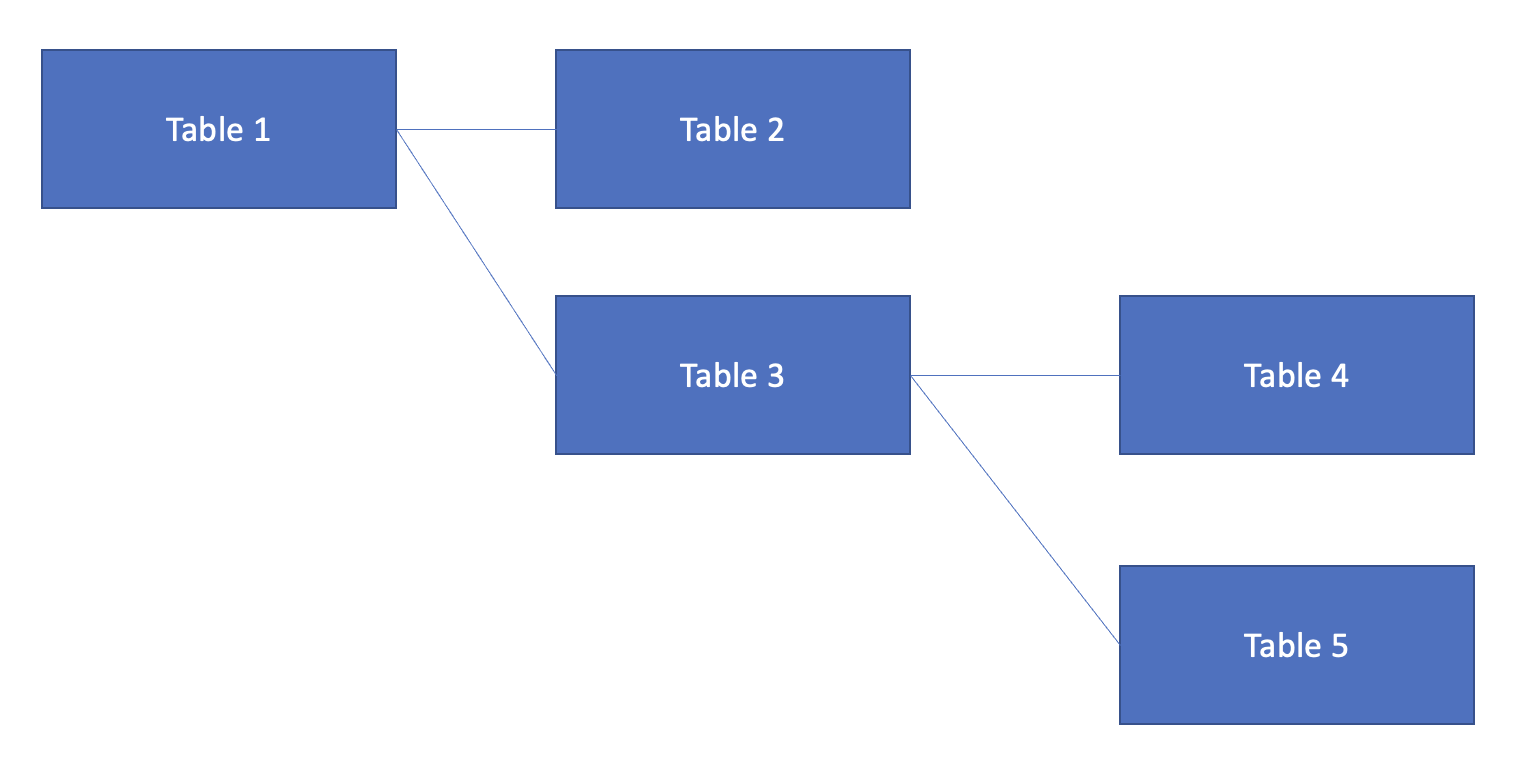
I'm trying to create one snowflake view using multiple tables. I understand that FROM...JOIN statements can combine multiple tables.
When I would like to join from one table that already has a join from another table, what is the best way to write a script? In this case, from Table 3, Table 4 and Table 5 are joined. The Table 3 is joined from Table 1.
CodePudding user response:
Your question is not clear, but normally all the tables are joined as follows
select *
from table1 t1
join table2 t2 on t1.id = t2.table1_ID
join table3 t3 on t1.id = t3.table1_ID
join table4 t4 on t3.id = t4.table3_ID
join table5 t5 on t3.id = t5.table3_ID
CodePudding user response:
Meysam answer is very valid, but I see there is more questions at hand.
Normally you can have a single block of SELECT and there all the TABLES in the FROM JOIN zone, and all the WHERE's you like, in modern form the WHERE's that belong to the JOINS and not filters, are put on the ON, thus Meysam's answer.
SELECT
t1.thing,
t2.other_thing,
t4.extra_detail,
t5.one_last_thing
FROM table1 t1
JOIN table2 t2
ON t1.id = t2.table1_ID
JOIN table3 t3
ON t1.id = t3.table1_ID
JOIN table4 t4
ON t3.id = t4.table3_ID
JOIN table5 t5
ON t3.id = t5.table3_ID
Now you mention a CTE which could be done on the table3 chain if there was merit like so:
WITH table_3_sub_chain_cte_of_merit AS (
SELECT
t3.table1_ID
t4.extra_detail,
t5.one_last_thing
FROM table3 t3
JOIN table4 t4
ON t3.id = t4.table3_ID
JOIN table5 t5
ON t3.id = t5.table3_ID
)
SELECT
t1.thing,
t2.other_thing,
cte3.extra_detail,
cte3.one_last_thing
FROM table1 t1
JOIN table2 t2
ON t1.id = t2.table1_ID
JOIN table_3_sub_chain_cte_of_merit cte3
ON t1.id = cte3.table1_ID
OR the CTE sub expression can be moved into a sub-select, if that had merit, like so:
SELECT
t1.thing,
t2.other_thing,
cte3.extra_detail,
cte3.one_last_thing
FROM table1 t1
JOIN table2 t2
ON t1.id = t2.table1_ID
JOIN (
SELECT
t3.table1_ID
t4.extra_detail,
t5.one_last_thing
FROM table3 t3
JOIN table4 t4
ON t3.id = t4.table3_ID
JOIN table5 t5
ON t3.id = t5.table3_ID
)cte3
ON t1.id = cte3.table1_ID
Now the interesting part, merit, why would we be doing these things.
The first version should meet your needs just fine if you want to just get some value off each table and move on. But if you are doing some complex filters on table3 and below, or you are doing some expensive aggregation on the table3 and below, but those result are match many times to table1, then doing the work in a CTE or sub-query makes sense.
Now why might you use the CTE over the subquery, the simple answer for the code given they are the same. But if you joined table1 and table3 multiple times, because you are calculated daily costs, weekly costs, and monthly costs, then build the costs once (in a CTE), and then joining those results can save a lot of time. But at the same time, sometimes CTE's can slow things down, as what might seem the "expensive code" is mostly free once the other work is taken into account, and thus I have seen code run faster on Snowflake doing a large aggregation three times in sub-selects as it removes the synchronization cost between the data paths, and the remote data read was the same bottle neck under both.
On the other hand sometime CTE's make reading the code cleaner, as you get to name the expression something meaningful, and then use an alias, so the SQL is more readable, but the intent is captured. And Snowflake optimizer rewrites the SQL anyways, some they can and are often the same. So helping humans is more value.
On other databases there optimizers can be helped by the order of the joins, and them being nested (or so I have been told) but I have not read/witnessed that on snowflake, but have spent days rewriting SQL to have it have the "same execution plan" in the other form.
But where CTE's shine can be in really large (hundreds of lines of SQL) in pushing filters to where you want them, to avoid really large data reads, and full table processing only to have that pruned. This sort of thing is spot able in the query profiler, but 10 billion rows going between blocks for many steps only to hit a filter later in the pipeline and 5 thousand coming out.
CodePudding user response:
You should be able to join exactly in the relation hierarchy you have listed such as
select
t1.*,
t2.whatever,
t3.whatever3,
t4.whatever4,
t5.whatever5
from
table1 t1
join table2 t2
on t1.t2id = t2.id
join table3 t3
on t1.t3id = t3.id
join table4 t4
on t3.t4id = t4.id
join table5 t5
on t3.t5id = t5.id
So, what is the confusion