Let's say we have a dictionary of dataframes with 900 dataframes.
Each dataframe has unique number of rows but same number of column (let's say 9) and same column names. Lets say a column named "C1" common to all dataframes in the dictionary of dataframes has integer values varying from 1 to 4000.
How can we create a dataframe by selecting a row corresponding to any unique value in C1 from each dataframe in the dictionary of dataframes? The resulting dataframe will have 900 rows and same number of columns as the original dataframe (i.e., 9).
We don't want C1 values selected from each dataframe in the dictionary to be same. We want different combinations of values.
Not all dataframes have the same set of C1 values. Some might have {11, 16, 20}, others might have {10, 16, 20}. We only want to create dataframes from the values that exist across all dataframes. So in this example, we only want dataframes where C1 values are either 16 or 20.
Can we also create possible combinations of such dataframes?
Example:
Let's say the dictionary of dataframe has four dataframes:
df1
C0 C1
a 1
a 2
a 3
df2
C0 C1
b 1
b 2
b 3
df3
C0 C1
c 1
c 2
c 3
df4
C0 C1
d 1
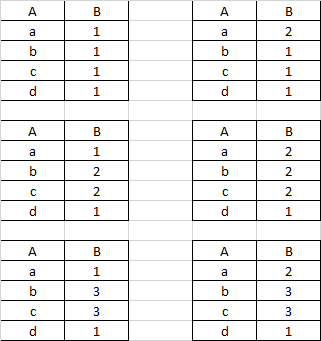
Example of few possible dataframes are given in the image below:
CodePudding user response:
Try:
# Setup
cols = [f"C{i}" for i in range(10)]
dfs = {i: pd.DataFrame(np.random.randint(1, 4000, (1500, 10)), columns=cols)
for i in range(900)}
excluded = []
data = []
for df in dfs.values():
row = df.loc[~df['C0'].isin(excluded)].sample(n=1)
excluded.append(row['C0'].squeeze())
data.append(row)
df = pd.concat(data).reset_index(drop=True)
Output:
>>> df.head()
C0 C1 C2 C3 C4 C5 C6 C7 C8 C9
0 430 1022 2094 345 1958 256 2142 3931 1030 800
1 3082 606 2657 2038 950 663 3037 1768 2471 2017
2 3075 2543 3046 790 588 1476 2562 2249 1457 1549
3 1636 3273 1585 1099 547 630 1958 3396 2110 117
4 3798 3933 2649 2234 3685 3509 3051 1970 1543 3685
>>> df['C0'].nunique()
900
>>> df.shape
(900, 10)
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 900 entries, 1 to 1499
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 C0 900 non-null int64
1 C1 900 non-null int64
2 C2 900 non-null int64
3 C3 900 non-null int64
4 C4 900 non-null int64
5 C5 900 non-null int64
6 C6 900 non-null int64
7 C7 900 non-null int64
8 C8 900 non-null int64
9 C9 900 non-null int64
dtypes: int64(10)
memory usage: 77.3 KB
Erratum: I used C0 as name instead of C1.