I'm following sentdex's youtube channel ML tutorial.
So as I was coding along on how to build your own KNN algorithm, I noticed that my accuracy was very low, in the 60s almost every time. I had made a few changes, but then I used his code line by line, and the same dataset, yet somehow he gets accuracies in the range of 95-98%, while mine is 60-70%. I'm really not able to figure out the reason behind such a huge difference.
I also have a second question which has to do with the confidence of the predictions. The value of the confidence is supposed to be within 0-1 right? But for me, they're all identical, and in the 70s. Let me explain with a screenshot
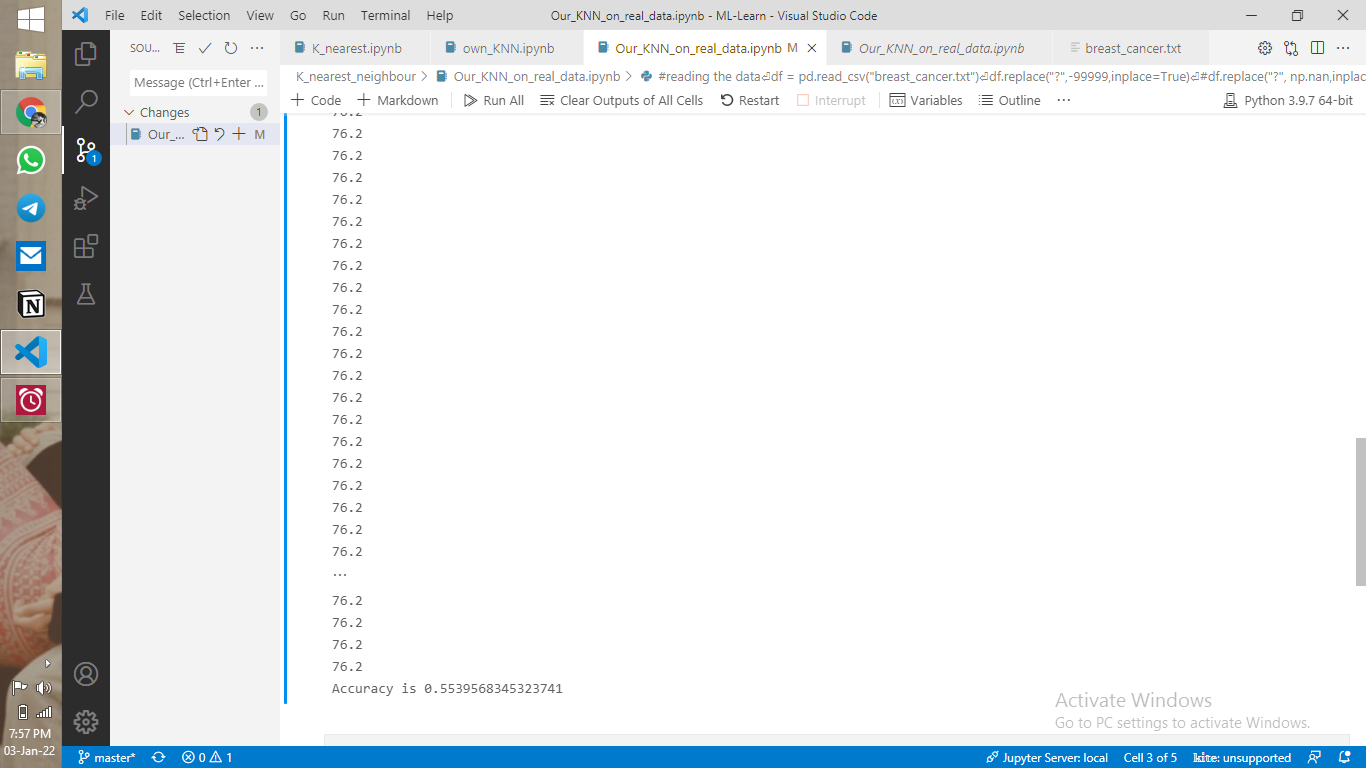
My code:
# Importing libraries
import numpy as np
import pandas as pd
from collections import Counter
import warnings
import random
# Algorithm
def k_nearest(data,predict,k=5):
if len(data)>=k:
warnings.warn("stupid, your data has more dimensions than prescribed")
distances = []
for group in data: # The groups of 2s and 4s
for features in data[group]: # values in 2 and 4 respectively
#euclidean_distance = np.sqrt(np.sum((np.array(features) - np.sum(predict)) **2))
euclidean_distance = np.linalg.norm(np.array(features) - np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)] # adding the sorted(ascending) group names
votes_result = Counter(votes).most_common(1)[0][0] # the most common element
confidence = float((Counter(votes).most_common(1)[0][1]))/float(k)#ocuurences of the most common element
return votes_result,confidence
#reading the data
df = pd.read_csv("breast_cancer.txt")
df.replace("?",-99999,inplace=True)
#df.replace("?", np.nan,inplace=True)
#df.dropna(inplace=True)
df.drop("id",axis = 1,inplace=True)
full_data = df.astype(float).values.tolist() # Converting to list because our function is written like that
random.shuffle(full_data)
#print(full_data[:10])
test_size = 0.2
train_set = {2:[],4:[]}
test_set = {2:[],4:[]}
train_data = full_data[:-int(test_size*len(full_data))] # Upto the last 20% of the og dateset
test_data = full_data[-int(test_size*len(full_data)):] # The last 20% of the dataset
# Populating the dictionary
for i in train_data:
train_set[i[-1]].append(i[:-1]) # appending with features and leaving out the label
for i in test_data:
test_set[i[-1]].append(i[:-1]) # appending with features and leaving out the label
# Testing
correct,total = 0,0
for group in test_set:
for data in test_set[group]:
vote,confidence = k_nearest(train_set, data,k=5)
if vote == group:
correct =1
else:
print(confidence)
total = 1
print("Accuracy is",correct/total)
Link to the dataset breast-cancer-wisconsin.data
CodePudding user response:
There's a mistake in your k_nearest function, you need to return only the top k of distances, not the whole list. So it should be:
votes = [i[1] for i in sorted(distances)[:k]]
Instead of in your code:
votes = [i[1] for i in sorted(distances)]
We can rewrite your function:
def k_nearest(data,predict,k=5):
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features) - np.array(predict))
distances.append([euclidean_distance,group])
votes = [i[1] for i in sorted(distances)[:k]]
votes_result = Counter(votes).most_common(1)[0][0]
confidence = float((Counter(votes).most_common(1)[0][1]))/float(k)
return votes_result,confidence
And run your code, I am not so sure about replacing "?" with -999 so I read it in as na :
import pandas as pd
from collections import Counter
import random
import numpy as np
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data'
df = pd.read_csv(url,header=None,na_values="?")
df = df.dropna()
full_data = df.iloc[:,1:].astype(float).values.tolist()
random.seed(999)
random.shuffle(full_data)
test_size = 0.2
train_set = {2:[],4:[]}
test_set = {2:[],4:[]}
train_data = full_data[:-int(test_size*len(full_data))]
test_data = full_data[-int(test_size*len(full_data)):]
for i in train_data:
train_set[i[-1]].append(i[:-1])
for i in test_data:
test_set[i[-1]].append(i[:-1])
correct,total = 0,0
for group in test_set:
for data in test_set[group]:
vote,confidence = k_nearest(train_set, data,k=5)
if vote == group:
correct =1
else:
print(confidence)
total = 1
print("Accuracy is",correct/total)
Gives:
1.0
0.8
1.0
0.6
0.6
0.6
0.6
Accuracy is 0.9485294117647058