I have a the below column which is in python dataframe
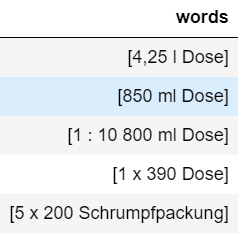
But, the expected output should be like
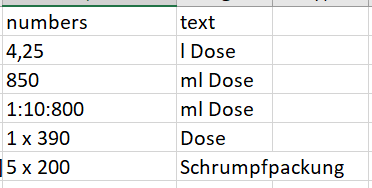
Any help in Python please?
CodePudding user response:
You can first extract value from the list with pandas.apply and then use Series.str.extract.
df['words'] = df['words'].apply(lambda x: x[0])
df = df.join(df['words'].str.extract(r'(.*\d) (.*)')
).rename(columns = {1:'text', 0:'numbers'}
).drop(columns='words')
print(df)
numbers text
0 4,25 I Dose
1 850 ml Dose
2 1: 10 800 ml Dose
3 1 x 390 Dose
4 5 x 200 Schrumpfpachung
CodePudding user response:
It's not clear from your question whether words contains strings with brackets in them or lists of one string each, so here are solutions for both cases.
DataFrame containing strings including square brackets:
pat='\[(.*\d) (.*)\]'
#pat='\[((?: *[^ ] ) ?) ((?:[a-zA-Z] *) )\]'
df = df.words.str.extract(pat).rename(columns={0:'numbers',1:'text'})
Input:
df = pd.DataFrame({
'words':['[4,25 l Dose]','[850 ml Dose]','[1 : 10 800 ml Dose]','[5 x 200 Schrumpfpackung]']
})
Output:
numbers text
0 4,25 l Dose
1 850 ml Dose
2 1 : 10 800 ml Dose
3 5 x 200 Schrumpfpackung
Explanation:
- using the
Series.str()accessor andextract(), extract the capture groups from the string in each item as two columns corresponding tonumbersandtextcolumns - rename the auto-generated columns labeled
0and1to have the desired labels (numbersandtext).
DataFrame containing lists with one string each:
pat='(.*\d) (.*)'
#pat='((?: *[^ ] ) ?) ((?:[a-zA-Z] *) )'
df = df.words.str.get(0).str.extract(pat).rename(columns={0:'numbers',1:'text'})
Input:
df = pd.DataFrame({
'words':[['4,25 l Dose'],['850 ml Dose'],['1 : 10 800 ml Dose'],['5 x 200 Schrumpfpackung']]
})
Output
same as above ...
Explanation:
- using the
Series.str()accessor to manipulate each element of typelist(slightly confusing as the accessor is namedstr()but is more generally applicable to pandas Series whose values are python sequences, including bothstrandlist) andget(), access the first (and only) string in eachlistin the columns - use
extract()to get the capture groups from the string in each item as two columns corresponding tonumbersandtextcolumns - rename the auto-generated columns labeled
0and1to have the desired labels (numbersandtext).
Note that either the pat used above or the one that is commented out will work for each respective case (string or list). I started with the commented-out pattern, but the pattern in the answer by @Pieter Geelen seems to work as well and is simpler, so I have included it (and a variant of it) above.
CodePudding user response:
you might want to try out Regex
With the pattern: (.*\d) (.*) you can already outline that you should have something that ends with a number, that is trailed with some describtion in words.
import re
some_strings = """4,25 l Dose
850 ml Dose
1: 10 800 ml Dose
1 x 390 Dose
5 x 200 Schrumpfverpackung """.split('\n')
for item in some_strings:
m = re.search("(.*\d) (.*)", item)
print(m.group(0))
print(m.group(1))
print(m.group(2))
That prints out
4,25 l Dose
4,25
l Dose
850 ml Dose
850
ml Dose
1: 10 800 ml Dose
1: 10 800
ml Dose
1 x 390 Dose
1 x 390
Dose
5 x 200 Schrumpfverpackung
5 x 200
Schrumpfverpackung
EDIT
For a pandas series you need to note that you need the iteritems method and use the second item in the tuple, as the first is the index itself.
import re
some_strings = pd.Series("""4,25 l Dose
850 ml Dose
1: 10 800 ml Dose
1 x 390 Dose
5 x 200 Schrumpfverpackung """.split('\n'))
for item in some_strings.iteritems():
m = re.search("(.*\d) (.*)", item[1])
print("first group:", m.group(0))
print("second group:", m.group(1))
print("third group:", m.group(2))