I want to drop the first row of a dataframe subset which is a subset of the main dataframe main. The first row of the dataframe has index = 31, so when I try dropping the first row I get the following error:
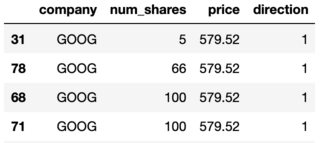
>>> subset.drop(0, axis=1)
KeyError: '[0] not found in axis'
I want to perform this drop on multiple dataframes, so I cannot drop index 31 on every dataframe. Is it possible to drop the first row when the index isn't equal to 0?
CodePudding user response:
Simpliest is select all rows without first by position:
df = df.iloc[1:]
Or with drop is possible select first value, but if duplicated values, then all rows are removed:
df = df.drop(df.index[0])
Your solution try remove column 0:
subset.drop(0, axis=1)
CodePudding user response:
df = df if df.index[0] == 0 else df.iloc[1:]