I will start by posting the code example that's been used to create a testcase (foo.xlsx) for this thread.
This simple code creates an xlsx file with numerical entries and formulas:
[boris@E7490-DELL temp]$ cat xlsx1.py
#!/bin/env python
import pandas as pd
d = {'col1': [7, 2, 5, 9, 1], 'col2': [3, 6, 6, 7, 9]}
df = pd.DataFrame(data=d)
writer = pd.ExcelWriter("foo.xlsx", engine="xlsxwriter")
df["prod"] = None
df["prod"] = (
'=INDIRECT("R[0]C[%s]", 0)*INDIRECT("R[0]C[%s]", 0)'
% (
df.columns.get_loc("col1") - df.columns.get_loc("prod"),
df.columns.get_loc("col2") - df.columns.get_loc("prod"),
)
)
df["sum"] = None
df["sum"] = (
'=SUM(INDIRECT("R[0]C[%s]:R[0]C[%s]",0))'
% (
df.columns.get_loc("col1") - df.columns.get_loc("sum"),
df.columns.get_loc("col2") - df.columns.get_loc("sum"),
)
)
df["max"] = None
df["max"] = (
'=MAX(INDIRECT("R[0]C[%s]:R[0]C[%s]",0))'
% (
df.columns.get_loc("col1") - df.columns.get_loc("max"),
df.columns.get_loc("col2") - df.columns.get_loc("max"),
)
)
df["min"] = None
df["min"] = (
'=MIN(INDIRECT("R[0]C[%s]:R[0]C[%s]",0))'
% (
df.columns.get_loc("col1") - df.columns.get_loc("min"),
df.columns.get_loc("col2") - df.columns.get_loc("min"),
)
)
print(df)
df.to_excel(writer, index=False)
writer.save()
CLI output after executing the above mentioned code, i.e. print(df):
[boris@E7490-DELL temp]$ ./xlsx1.py
col1 col2 prod sum max min
0 7 3 =INDIRECT("R[0]C[-2]", 0)*INDIRECT("R[0]C[-1]"... =SUM(INDIRECT("R[0]C[-3]:R[0]C[-2]",0)) =MAX(INDIRECT("R[0]C[-4]:R[0]C[-3]",0)) =MIN(INDIRECT("R[0]C[-5]:R[0]C[-4]",0))
1 2 6 =INDIRECT("R[0]C[-2]", 0)*INDIRECT("R[0]C[-1]"... =SUM(INDIRECT("R[0]C[-3]:R[0]C[-2]",0)) =MAX(INDIRECT("R[0]C[-4]:R[0]C[-3]",0)) =MIN(INDIRECT("R[0]C[-5]:R[0]C[-4]",0))
2 5 6 =INDIRECT("R[0]C[-2]", 0)*INDIRECT("R[0]C[-1]"... =SUM(INDIRECT("R[0]C[-3]:R[0]C[-2]",0)) =MAX(INDIRECT("R[0]C[-4]:R[0]C[-3]",0)) =MIN(INDIRECT("R[0]C[-5]:R[0]C[-4]",0))
3 9 7 =INDIRECT("R[0]C[-2]", 0)*INDIRECT("R[0]C[-1]"... =SUM(INDIRECT("R[0]C[-3]:R[0]C[-2]",0)) =MAX(INDIRECT("R[0]C[-4]:R[0]C[-3]",0)) =MIN(INDIRECT("R[0]C[-5]:R[0]C[-4]",0))
4 1 9 =INDIRECT("R[0]C[-2]", 0)*INDIRECT("R[0]C[-1]"... =SUM(INDIRECT("R[0]C[-3]:R[0]C[-2]",0)) =MAX(INDIRECT("R[0]C[-4]:R[0]C[-3]",0)) =MIN(INDIRECT("R[0]C[-5]:R[0]C[-4]",0))
foo.xlsx file content (the screenshot shows the foo.xlsx as displayed by LibreOffice Calc)
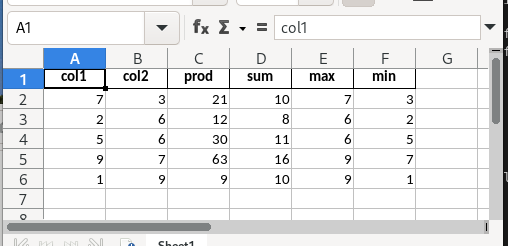
So that's how my testcase (foo.xlsx) is created. This xlsx contains only numerical values, of which some are integers and some are calculated by formulas. Now I would like to read this xlsx file in pandas data-frame for post-processing (don't need the formulas, but the actual values calculated by the formulas). I've tried two methods (both unsuccessful) that will be explained next...
Method 1) is using pandas.read_excel:
The Code:
[boris@E7490-DELL temp]$ cat xlsx2.py
#!/bin/env python
import pandas as pd
read_file = pd.read_excel("foo.xlsx")
print(read_file)
read_file.to_csv ("foo.csv", index = None, header=True)
CLI output:
[boris@E7490-DELL temp]$ ./xlsx2.py
col1 col2 prod sum max min
0 7 3 0 0 0 0
1 2 6 0 0 0 0
2 5 6 0 0 0 0
3 9 7 0 0 0 0
4 1 9 0 0 0 0
foo.csv file content:
[boris@E7490-DELL temp]$ cat foo.csv
col1,col2,prod,sum,max,min
7,3,0,0,0,0
2,6,0,0,0,0
5,6,0,0,0,0
9,7,0,0,0,0
1,9,0,0,0,0
Method 2) is using openpyxl.load_workbook:
The Code:
[boris@E7490-DELL temp]$ cat xlsx3.py
#!/bin/env python
import pandas as pd
from openpyxl import load_workbook
wb = load_workbook("foo.xlsx", data_only=True)
ws = wb['Sheet1']
df = pd.DataFrame(ws.values)
print(df.head())
df.to_csv ("foo.csv", index = None, header=True)
CLI output:
[boris@E7490-DELL temp]$ ./xlsx3.py
0 1 2 3 4 5
0 col1 col2 prod sum max min
1 7 3 0 0 0 0
2 2 6 0 0 0 0
3 5 6 0 0 0 0
4 9 7 0 0 0 0
foo.csv file content:
[boris@E7490-DELL temp]$ cat foo.csv
0,1,2,3,4,5
col1,col2,prod,sum,max,min
7,3,0,0,0,0
2,6,0,0,0,0
5,6,0,0,0,0
9,7,0,0,0,0
1,9,0,0,0,0
Both methods have failed to get the numerical values out of the xlsx. I'm stuck here, any help is highly appreciated.
CodePudding user response:
Bit of a workaround here, not a real explanation for what is happening, but...
I'm getting the same thing as you, but if I open the excel file and just save it, then reading it in pandas gives the numbers you want. So try that, just opening excel and saving it. You could easily enough script that.
CodePudding user response:
As I don't have an idea how to automate this further, I'll just go with a headless execution:
soffice --headless --convert-to csv foo.xlsx
foo.csv file content:
[boris@E7490-DELL temp]$ cat foo.csv
col1,col2,prod,sum,max,min
7,3,21,10,7,3
2,6,12,8,6,2
5,6,30,11,6,5
9,7,63,16,9,7
1,9,9,10,9,1
Then I'll be reading this csv file to pandas data-frame for post-processing.