I need to create multiple columns in a data frame based on the new columns. For this aim, I have a loop that works fine but requires quite a lot of time to produce the result. May you suggest me a more efficient approach than my loop? Happy if this has a dplyr/purrr approach such as map().
I put here a very simplified version of my real (more complicated and larger) code.
Defining input data for the function:
df <-
data.frame(data_2010 = c(1,2,3,4))
# Start and dnd of the loop
year_loopStart <- 2011
year_loopEnd <- 2015
Creating the function with a loop inside:
fun_lag <-
function(df, year_loopStart, year_loopEnd){
output <- df
for(y in c(year_loopStart : year_loopEnd)){
# Calculate population for the next years without considering the effect of air pollution
# Calculate population in the next years based on the row above
output <-
output%>%
dplyr::mutate(
"data_{y}" :=
dplyr::lag(!!as.symbol(paste0("data_", y-1))))
}
return(output)
}
Running the function with the loop (right output but slow when applied to many columns):
test1 <-
fun_lag(df, year_loopStart, year_loopEnd)
Desired output (obtained with fun_lag but it is slow):
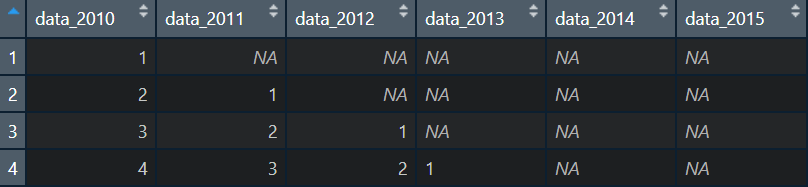
Failed attempt to use map() instead of a loop:
test2 <-
map_dfc(year_loopStart:year_loopEnd,
~ mutate(df,
"data_{.x}" :=
dplyr::lag(!!as.symbol(paste0("data_", .x -1)))))
Error message:
Error: Problem with `mutate()` column `data_2012`.
i `data_2012 = dplyr::lag(data_2011)`.
x Object 'data_2011' not found
CodePudding user response:
You may pass different n value for lag using imap -
library(dplyr)
library(purrr)
bind_cols(df,
imap_dfc(year_loopStart:year_loopEnd,
~df %>% transmute("data_{.x}" := lag(data_2010, .y))))
# data_2010 data_2011 data_2012 data_2013 data_2014 data_2015
#1 1 NA NA NA NA NA
#2 2 1 NA NA NA NA
#3 3 2 1 NA NA NA
#4 4 3 2 1 NA NA