I have this code where lig_dec_residue is this nested dictionary which comes from big .dat files:
lig_dec_residue = {'f1': {}, 'f2': {}, 'f3': {}}
def plot_lig(res):
df = pd.DataFrame.from_dict(lig_dec_residue)
df.index = df.index.str.split(' ')
df.index = df.index.str[0] ' ' (df.index.str[1].astype(int) int(res) - 1).astype(str)
df = df[df <= -0.25]
df.dropna(how='all', inplace=True)
df.plot(kind='bar', edgecolor='black')
plt.legend(['X var', 'Y var', 'Z var'])
plt.show()
plt.close()
and this is the result:
f1 f2 f3
ARG 403 -0.265999 NaN -0.390653
LEU 455 -1.948253 -2.125521 -1.988445
PHE 456 -1.974429 -1.835651 -2.177540
ALA 475 -0.796856 -1.032929 -0.968554
GLY 476 -0.262736 -0.744952 -0.257448
ASN 477 NaN NaN -0.868419
PHE 486 -3.674621 -2.882512 -3.179725
ASN 487 -1.172256 -0.805725 -1.050299
LYS 493 -2.283489 NaN -5.231593
SER 496 NaN NaN -0.366986
PHE 497 NaN -0.340862 NaN
ARG 498 -1.485091 NaN -1.140743
THR 500 -1.497597 -0.778616 -1.961580
TYR 501 -4.286950 NaN -4.851700
GLY 502 -0.447453 -0.808606 -0.702321
VAL 503 -0.256496 -0.371461 -0.977062
HIS 505 -1.420959 NaN -1.321259
LYS 417 NaN -1.115154 NaN
GLN 493 NaN -2.625195 NaN
GLY 496 NaN -1.232041 NaN
GLN 498 NaN -2.271338 NaN
ASN 501 NaN -4.152646 NaN
TYR 505 NaN -2.469813 NaN
Pandas plots the last six entries apart from the rest (look at TYR 501, ASN 501: they should be close but they are not!).
The idea is to make a comparison between f1 f2 and f3 with a bar plot.
This is my output:
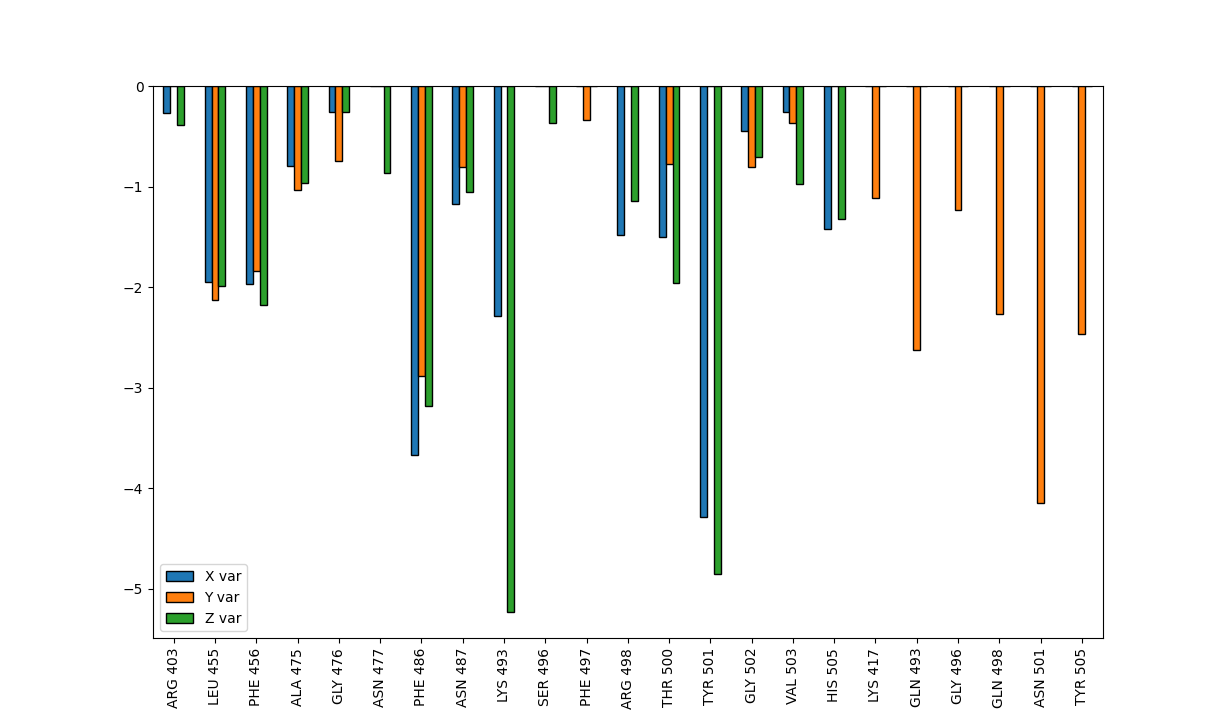
Is there a way to sort the index properly? I think this output might be due to the lexicographic sorting method. I know that there's natsort library, but I can't make use of if since the dataframes comes from nested dictionaries. I would like to group the bars based on the number of the index (eg, HIS 505 next to TYR 505) for a direct comparison where applicable.
Thank you!
Ludovico
CodePudding user response:
Use sort_index with a custom key:
df = df.sort_index(key=lambda x: x.str.split().str[1].str.zfill(5))
print(df)
# Output
f1 f2 f3
ARG 403 -0.265999 NaN -0.390653
LYS 417 NaN -1.115154 NaN
LEU 455 -1.948253 -2.125521 -1.988445
PHE 456 -1.974429 -1.835651 -2.177540
ALA 475 -0.796856 -1.032929 -0.968554
GLY 476 -0.262736 -0.744952 -0.257448
ASN 477 NaN NaN -0.868419
PHE 486 -3.674621 -2.882512 -3.179725
ASN 487 -1.172256 -0.805725 -1.050299
LYS 493 -2.283489 NaN -5.231593
GLN 493 NaN -2.625195 NaN
SER 496 NaN NaN -0.366986
GLY 496 NaN -1.232041 NaN
PHE 497 NaN -0.340862 NaN
GLN 498 NaN -2.271338 NaN
ARG 498 -1.485091 NaN -1.140743
THR 500 -1.497597 -0.778616 -1.961580
TYR 501 -4.286950 NaN -4.851700
ASN 501 NaN -4.152646 NaN
GLY 502 -0.447453 -0.808606 -0.702321
VAL 503 -0.256496 -0.371461 -0.977062
HIS 505 -1.420959 NaN -1.321259
TYR 505 NaN -2.469813 NaN
Detail about the key:
>>> df.index.str.split().str[1].str.zfill(5)
Index(['00403', '00455', '00456', '00475', '00476', '00477', '00486', '00487',
'00493', '00496', '00497', '00498', '00500', '00501', '00502', '00503',
'00505', '00417', '00493', '00496', '00498', '00501', '00505'],
dtype='object')
Note: padding with 0 allow you to have a natural sorting when two numbers have not the same length:
>>> '23' > '5'
False
>>> '23' > '05'
True