data = {'city':['Austin TX', 'Austin TX', 'Austin TX', 'Columbus OH', 'Columbus OH', 'Columbus OH', 'Columbus OH', 'Dallas TX', 'Dallas TX' , 'Dallas TX', 'Dallas TX' , 'Dallas TX'],
'a1':[20, 200, 300, 400, 1000, 500, 800, 900, 900, 1000, 200, 450], 'a2':[30, 100, 1000, 500, 400, 600, 340, 430, 230, 450, 670, 780]}
I would like to check if city from second row is same as first row and if it is, then I have to get the data for that city. The final output I need is separate data frame or excel sheet or csv containing data for each of the cities. For example, for Austin TX, there would be one excel sheet named 'Austin_excel' that contains data for Austin which will be first 3 rows of a1, a2 and city.
CodePudding user response:
I think this is what you want -
import pandas as pd
df = pd.DataFrame(data)
workbook = pd.ExcelWriter("City Data.xlsx", engine="xlsxwriter")
for city, city_data in df.groupby("city"):
city_data.to_excel(workbook, sheet_name=city)
workbook.save()
The output looks like -
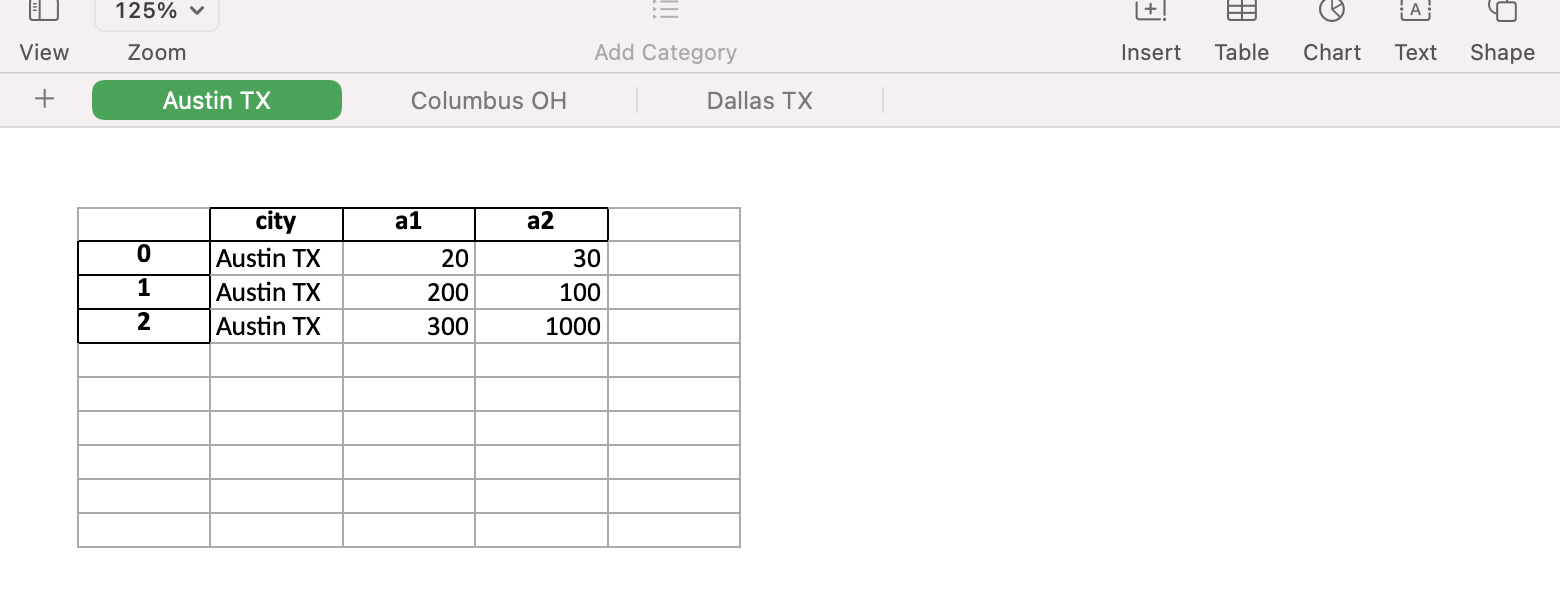
The data are in separate sheets of the Excel workbook as required.
CodePudding user response:
You can export Pandas DataFrame to an Excel file using to_excel.
Here is a template that you may apply in Python to export your DataFrame:
df.to_excel(r'Path where the exported excel file will be stored\File Name.xlsx', index = False) For instance:
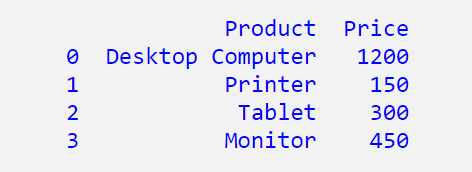
import pandas as pd
data = {'Product': ['Desktop Computer','Printer','Tablet','Monitor'],
'Price': [1200,150,300,450]
}
df = pd.DataFrame(data, columns = ['Product', 'Price'])
print (df)
Then you may got this: