from scrapy import Spider
from scrapy.http import Request
class AuthorSpider(Spider):
name = 'book'
start_urls = ['https://www.amazon.com/s?k=school bags&rh=n:1069242&ref=nb_sb_noss']
def parse(self, response):
books = response.xpath("//h2/a/@href").extract()
for book in books:
url = response.urljoin(book)
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
table=response.xpath("//table[@id='productDetails_detailBullets_sections1']").extract_first()
yield{
't':table
}
I am trying to scrape the table but I do not how to extract text from table trying to scrape product information this is the link in which I extract the table
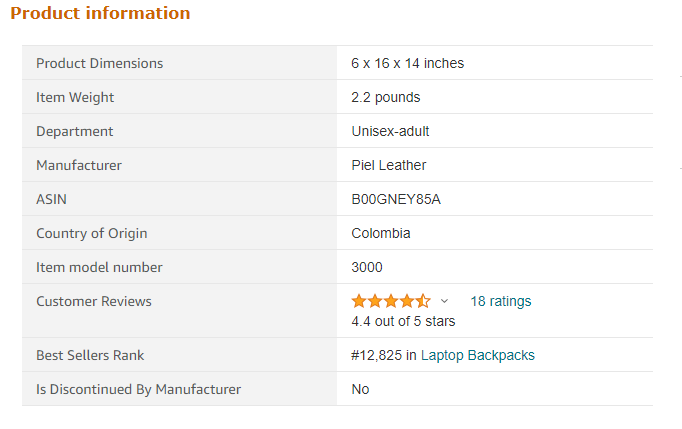
CodePudding user response:
To scrape a table, you can iterate through the table header and table data and assign them to keys and values and then yield the full dictonary. See below sample
from scrapy import Spider
from scrapy.http import Request
class AuthorSpider(Spider):
name = 'book'
start_urls = ['https://www.amazon.com/s?k=school bags&rh=n:1069242&ref=nb_sb_noss']
def parse(self, response):
books = response.xpath("//h2/a/@href").extract()
for book in books:
url = response.urljoin(book)
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
details = {}
for product_detail in response.xpath("//*[contains(@id,'productDetails')]//table/tr"):
key = product_detail.xpath("normalize-space(./th/text())").get()
value = product_detail.xpath("normalize-space(./td/text())").get().replace("\u200e", "")
if "best sellers rank" in key.lower():
det_list = product_detail.xpath("./td/descendant::*/text()").getall()
value = "".join([i.strip() for i in det_list])
if "customer reviews" in key.lower():
det_list = product_detail.xpath("./td/descendant::span/text()").getall()
value = " ".join([i.strip() for i in det_list])
details[key] = value
yield details
CodePudding user response:
It will only work for this kind of table like you have in your question:
from scrapy import Spider
from scrapy.http import Request
class AuthorSpider(Spider):
name = 'book'
start_urls = ['https://www.amazon.com/s?k=school bags&rh=n:1069242&ref=nb_sb_noss']
def parse(self, response):
books = response.xpath("//h2/a/@href").extract()
for book in books:
url = response.urljoin(book)
# just for the example
url='https://www.amazon.com/Piel-Leather-Double-Flap-Over-Backpack/dp/B00GNEY85A/ref=sr_1_1_sspa?keywords=school+bags&qid=1642846253&s=office-products&sr=1-1-spons&spLa=ZW5jcnlwdGVkUXVhbGlmaWVyPUExMkdMT1hKSkI1UVFTJmVuY3J5cHRlZElkPUEwNTQxMDA5M0c1R0xRQVUwTVdKViZlbmNyeXB0ZWRBZElkPUEwNzc5Njc4MUdQR09VMVBGSTlGSSZ3aWRnZXROYW1lPXNwX2F0ZiZhY3Rpb249Y2xpY2tSZWRpcmVjdCZkb05vdExvZ0NsaWNrPXRydWU&th=1'
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
rows = response.xpath('//div[@id="prodDetails"]//tr')
table = {}
for row in rows:
key = row.xpath('.//th//text()').get(default='').strip()
# this will work for most of the rows (except "Customer Reviews" and "Best Sellers Rank"):
# value = line.xpath('.//td//text()').get(default='').strip()
# this will work for all the rows
value = row.xpath('.//td/text() | .//td//span/text()').getall()
value = ''.join(value).strip()
table.update({key: value})
yield table
This is just an example. You need to check for the different types of tables you can get and adjust your code accordingly.
What we're doing is going through the table line by line and extracting the text from it, then appending adding it to a dictionary and eventually yielding it.
To get the text we're using /text(). Search for xpath cheat sheet it will help you.