I have a dataframe like as shown below
df = pd.DataFrame(
{'sub_code' : [np.nan, 'CSE01', np.nan,
'CSE02', 'CSE03', 'CSE02',
'CSE03', 'CSE02'],
'stud_level' : [101, 101, 101, 101,
101, 101, 101, 101],
'grade' : ['STA','STA','PSA','STA','STA','SSA','PSA','QSA']})
I would like to do the below
a) Fill NA's in sub_code column by referring grade column.
b) For ex: grade STA has corresponding sub_code non-NA values in row 1,3 and 4 (row 0 has NA value)
c) Copy the very 1st non-NA (CSE01) value from grade column and put it in sub_code column (row 0)
I tried the below
m = df['sub_code'].isna()
df.loc[m, 'sub_code'] = np.where(df.loc[m, 'grade'].ne(np.nan), df['sub_code'], 'not filled')
I expect my output to be like as below
CodePudding user response:
groupby "grade" and use first to get the first non-NaN sub_code in each grade. Then use np.where to fill NaN values in "sub_code":
mapper = df.groupby('grade')['sub_code'].first()
df['sub_code'] = np.where(df['sub_code'].isna(), df['grade'].map(mapper), df['sub_code'])
or instead of the second line, you can also use fillna:
df['sub_code'] = df.set_index('grade')['sub_code'].fillna(mapper)
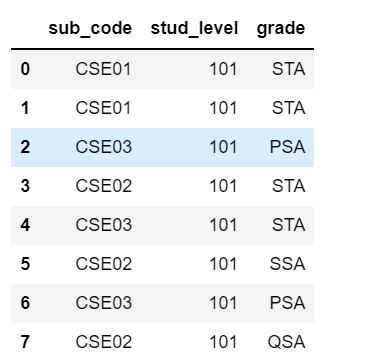
Output:
sub_code stud_level grade
0 CSE01 101 STA
1 CSE01 101 STA
2 CSE03 101 PSA
3 CSE02 101 STA
4 CSE03 101 STA
5 CSE02 101 SSA
6 CSE03 101 PSA
7 CSE02 101 QSA
CodePudding user response:
df['sub_code'] =df.groupby(['grade'])['sub_code'].bfill()
sub_code stud_level grade
0 CSE01 101 STA
1 CSE01 101 STA
2 CSE03 101 PSA
3 CSE02 101 STA
4 CSE03 101 STA
5 CSE02 101 SSA
6 CSE03 101 PSA
7 CSE02 101 QSA