I want to perform bootstrap on this data set. Notice that the data has two factors: replicate and level, and two variables high.density and low.density that need to be regressed. I want to perform a bootstrap on this data-set but the replacements can occur only within the nested factor of replicate and level.
replicate level high.density low.density
1 low 14 36
1 low 54 31
1 mid 82 10
1 mid 24 NA
2 low 12 28
2 low 11 45
2 mid 12 17
2 mid NA 24
2 up 40 10
2 up NA 5
2 up 20 2
For instance, in replicate/ level: 1/low the low.density 31 and 36 can be interchanged (or high.density interchanged) so the head of that dataset may look like:
replicate level high.density low.density
1 low 14 31
1 low 54 36
1 mid 82 10
1 mid 24 NA
I then want to estimate the linear regression (glm) from this dataset. I would appreciate any feedback on trying to achieve this.
##DATA FRAME (credits: caldwellst)
df <- structure(list(replicate = c(1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2), level = c("low", "low", "mid", "mid", "low", "low", "mid", "mid", "up", "up", "up"), high.density = c(14, 54, 82, 24, 12, 11, 12, NA, 40, NA, 20), low.density = c(36, 31, 10,
NA, 28, 45, 17, 24, 10, 5, 2)), class = c("spec_tbl_df","tbl_df","tbl", "data.frame"), row.names = c(NA, -11L), spec = structure(list(cols = list(replicate = structure(list(), class = c("collector_double", "collector")), level = structure(list(), class = c("collector_character","collector")), high.density = structure(list(), class = c("collector_double","collector")), low.density = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess", "collector")), skip = 1L), class = "col_spec"))
df$replicate <- as.factor(as.numeric(df$replicate))
df$level <- as.factor(as.character(df$level)
)
CodePudding user response:
Here's a solution using dplyr, purrr, and tidyr. First nest the numeric data, and then sample each of the unique combinations of replicate and level in the data. Then within those, bootstrap the unique values of the densities and then unnest for final data frame.
# library(tidyverse)
library(dplyr)
library(tidyr)
library(purrr)
df %>%
nest(data = ends_with("density")) %>%
slice_sample(n = 500, replace = TRUE) %>%
mutate(data = map(data, ~summarize(.x, across(.fns = sample, size = 1)))) %>%
unnest(cols = data)
#> # A tibble: 500 × 4
#> replicate level high.density low.density
#> <dbl> <chr> <dbl> <dbl>
#> 1 1 low 54 31
#> 2 2 mid 12 24
#> 3 1 mid 24 10
#> 4 2 up 20 2
#> 5 2 mid 12 24
#> 6 2 mid 12 24
#> 7 1 mid 82 10
#> 8 2 up NA 2
#> 9 1 low 14 36
#> 10 2 mid 12 17
#> # … with 490 more rows
Data
df <- structure(list(replicate = c(1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2),
level = c("low", "low", "mid", "mid", "low", "low", "mid",
"mid", "up", "up", "up"), high.density = c(14, 54, 82, 24,
12, 11, 12, NA, 40, NA, 20), low.density = c(36, 31, 10,
NA, 28, 45, 17, 24, 10, 5, 2)), class = c("spec_tbl_df",
"tbl_df", "tbl", "data.frame"), row.names = c(NA, -11L), spec = structure(list(
cols = list(replicate = structure(list(), class = c("collector_double",
"collector")), level = structure(list(), class = c("collector_character",
"collector")), high.density = structure(list(), class = c("collector_double",
"collector")), low.density = structure(list(), class = c("collector_double",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), skip = 1L), class = "col_spec"))
CodePudding user response:
We may exploit split and do the sampling according to unique combinations of replicate and level. We could repeat this process B times.
df_shuffle <- function(DF) {
my_split <- split(DF, f = ~ DF$replicate DF$level)
shuffle <- lapply(my_split, \(x) {
nrX <- nrow(x)
cbind(x[, c('replicate', 'level')],
high.density = x[sample(seq_len(nrX), replace = TRUE), 'high.density'],
low.density = x[sample(seq_len(nrX), replace = TRUE), 'low.density'])
})
DF_new <- do.call(rbind, shuffle)
rownames(DF_new) <- NULL
return(DF_new)
}
B <- 1000L
df_list <- replicate(B, df_shuffle(df), simplify = FALSE)
# ---------------------------------------------------
> df_list[[B]]
replicate level high.density low.density
1 1 low 54 36
2 1 low 54 36
3 2 low 12 45
4 2 low 12 28
5 1 mid 24 10
6 1 mid 82 10
7 2 mid NA 17
8 2 mid 12 17
9 2 up 20 10
10 2 up 40 10
11 2 up 20 5
Because the original data contains missing observations, we either have to multiply impute them or opt to lisewise delete them. For now, let's perform the latter option.
# listwise delete missing observations
df_list <- lapply(df_list, function(x) x[complete.cases(x), ])
Finally, we perform a linear regression on each shuffled dataset and store the B coefficients in out.
row_bind <- function(x) data.frame(do.call(rbind, x))
out <- row_bind(
lapply(df_list, function(x) lm(high.density ~ low.density, data = x)$coef)
)
## out <- row_bind(
## lapply(df_list, function(x) glm(replicate ~ low.density, data = x,
## family = binomial())$coef)
## )
# -------------------------------------------------------------------
> dim(out)
[1] 1000 2
Output
> head(out)
X.Intercept. low.density
1 13.74881 0.2804738
2 20.01074 -0.2095672
3 30.26643 -0.2946373
4 29.19541 -0.2752761
5 37.76273 -0.4555651
6 37.72250 -0.1548349
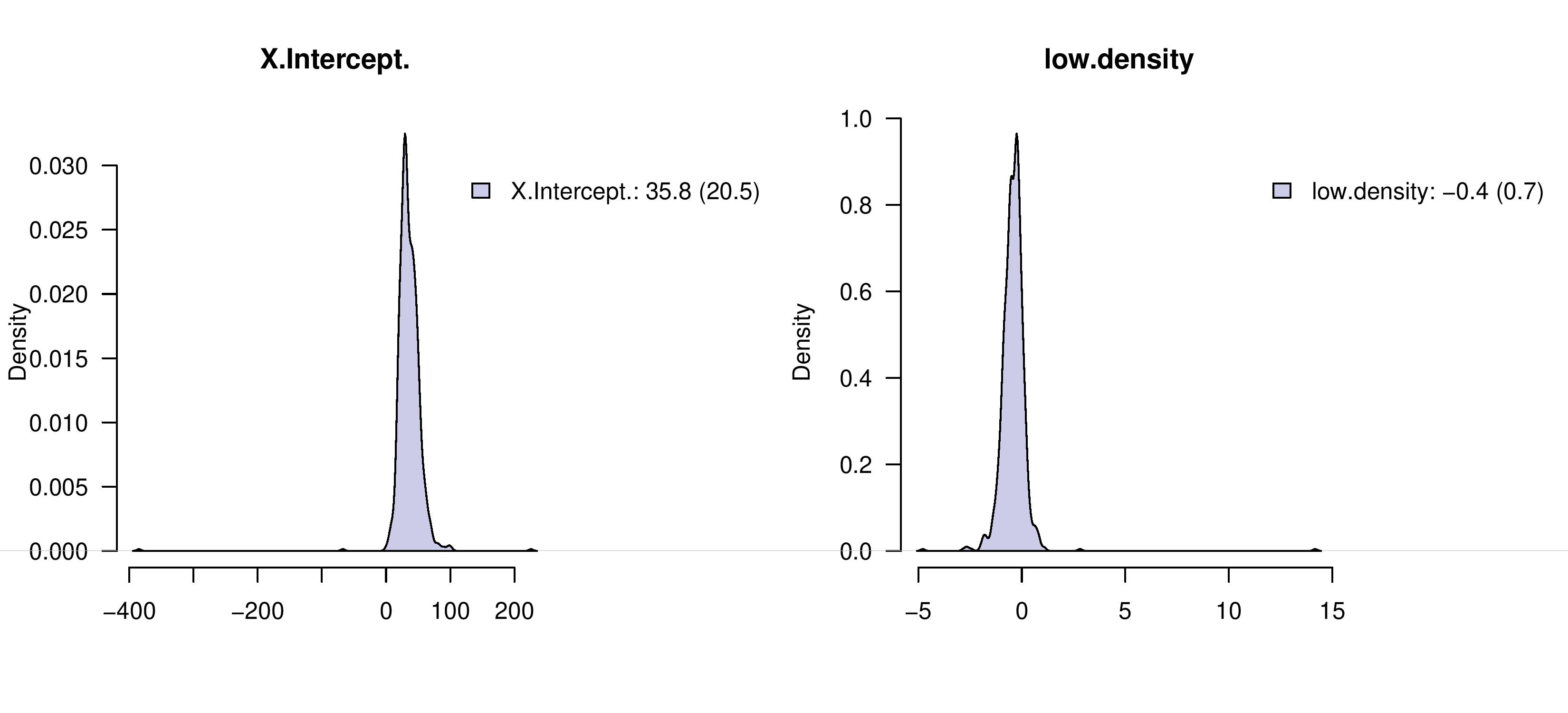
The code required to create this image can be found here.