New to R so no idea about it. I have a data of 64 samples (AML disease vs Control) and 22283 genes expression value of each sample. The data looks like this.
| GSM239170 | GSM239323 | GSM239324 | GSM239326 | GSM239328 | GSM239329 | GSM239331 | GSM239332 | GSM239333 |
|---|---|---|---|---|---|---|---|---|
| 3.016704177 | 3.285669072 | 2.929482692 | 2.922820483 | 3.15950317 | 3.163327169 | 2.985901308 | 3.122708843 | 3.070948463 |
| 7.977735461 | 6.532514237 | 6.388007183 | 6.466679556 | 6.432795021 | 6.407321524 | 6.426470803 | 6.376394357 | 6.469070308 |
| 4.207280707 | 4.994965767 | 4.40159671 | 4.747114589 | 4.830045513 | 4.213762092 | 4.884418365 | 4.4318876 | 4.849665444 |
| 7.25609471 | 7.420807337 | 6.999340125 | 7.094488581 | 7.024332721 | 7.17928981 | 7.159898654 | 7.009977785 | 6.830979234 |
| 2.204955099 | 2.331625217 | 2.133305231 | 2.18332885 | 2.12778313 | 2.269697813 | 2.264705552 | 2.253940441 | 2.287924323 |
| 7.28437278 | 6.983593721 | 6.86337111 | 6.865970678 | 7.219840938 | 7.181113053 | 7.392230178 | 7.484052914 | 7.52498281 |
| 4.265792764 | 4.970684112 | 4.595545125 | 4.575545289 | 4.547957809 | 4.68215122 | 4.674495889 | 4.675841709 | 4.643311767 |
| 2.6943516 | 2.916324936 | 2.578130269 | 2.659717988 | 2.567436676 | 2.8095128 | 2.790110381 | 2.795882913 | 2.884588792 |
| 3.646303109 | 8.817891552 | 11.4248793 | 10.74738082 | 9.296043108 | 9.53150669 | 8.285160496 | 9.769919327 | 9.774610531 |
| 3.040292001 | 3.38486713 | 2.958851115 | 3.047880699 | 2.878562717 | 3.209319974 | 3.20260379 | 3.195993624 | 3.3004227 |
| 2.357625231 | 2.444753172 | 2.340767158 | 2.32143889 | 2.282608342 | 2.401218719 | 2.385568421 | 2.375334953 | 2.432634747 |
| 5.378494673 | 6.065038394 | 5.134842087 | 5.367342376 | 5.682051149 | 5.712072512 | 5.57179966 | 5.72082395 | 5.656674512 |
| 2.833814735 | 3.038434511 | 2.837711812 | 2.859800224 | 2.866040813 | 2.969167906 | 2.929449968 | 2.963530689 | 2.931065261 |
| 6.192932281 | 6.478439634 | 6.180169144 | 6.151689376 | 6.238949956 | 6.708196123 | 6.441437631 | 6.448280595 | 6.413562269 |
| 4.543042482 | 4.786227217 | 4.445131477 | 4.51471011 | 4.491645167 | 4.460114204 | 4.602482637 | 4.587221948 | 4.623125028 |
| 6.069437462 | 6.232738284 | 6.74644117 | 7.04995802 | 6.938928532 | 6.348253102 | 6.080950712 | 6.324619355 | 6.472893789 |
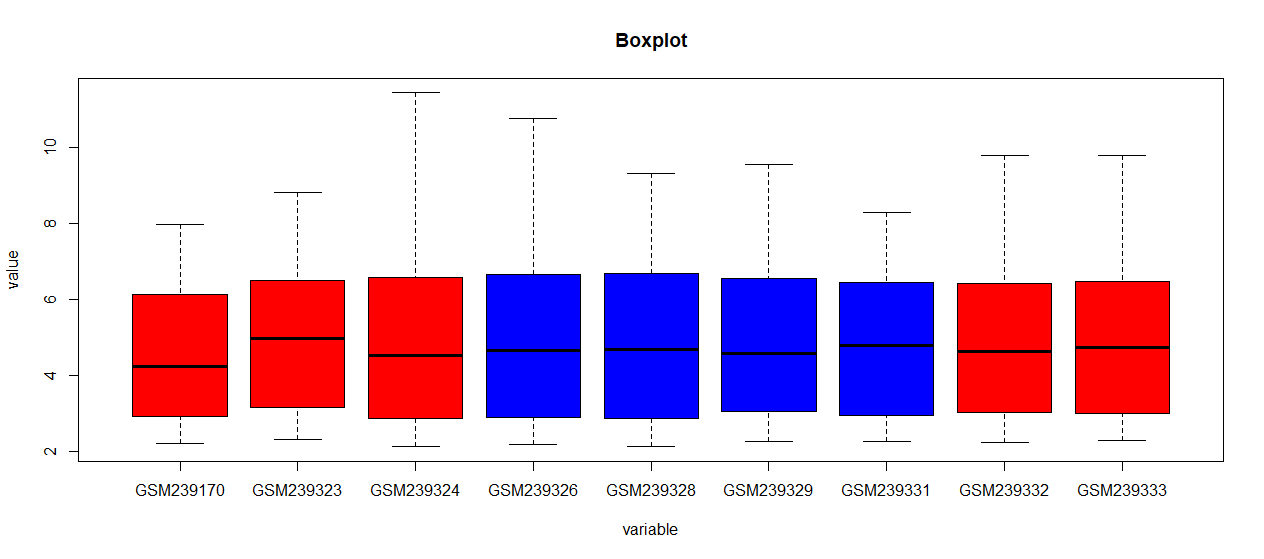
Where (GSM239170, GSM239323, GSM239324, GSM239332, GSM239333) are AML samples and (GSM239326, GSM239328, GSM239329, GSM239331) are Control samples. I want to make a Boxplot of gene expression for all the samples, marking data points in red for AML samples and blue for Control samples.
I tried the following code, but got the error.
boxplot(df1, main = "Boxplot")
Error in x[floor(d)] x[ceiling(d)] : non-numeric argument to binary operator
And with this code,
meltData <- melt(df1)
boxplot(meltData, main = "Boxplot")
# Error
meltData <- melt(df1)
Using Probe_ID as id variables
boxplot(meltData, main = "Boxplot")
Error in x[floor(d)] x[ceiling(d)] :
non-numeric argument to binary operator
How I can make the boxplot?
Thanks.
CodePudding user response:
To color the AML and Control red and blue, respectively, match the names(df1) to the AML vector and use it to index a vector of color values.
meltData <- reshape2::melt(df1)
aml <- scan(text="GSM239170, GSM239323, GSM239324, GSM239332, GSM239333", what = character(), sep = ",")
aml <- trimws(aml)
i_aml <- (names(df1) %in% aml) 1L
colors <- c("blue", "red")
boxplot(value ~ variable, meltData, main = "Boxplot", col = colors[i_aml])
Data
df1 <-
structure(list(GSM239170 = c(3.016704177, 7.977735461, 4.207280707,
7.25609471, 2.204955099, 7.28437278, 4.265792764, 2.6943516,
3.646303109, 3.040292001, 2.357625231, 5.378494673, 2.833814735,
6.192932281, 4.543042482, 6.069437462), GSM239323 = c(3.285669072,
6.532514237, 4.994965767, 7.420807337, 2.331625217, 6.983593721,
4.970684112, 2.916324936, 8.817891552, 3.38486713, 2.444753172,
6.065038394, 3.038434511, 6.478439634, 4.786227217, 6.232738284
), GSM239324 = c(2.929482692, 6.388007183, 4.40159671, 6.999340125,
2.133305231, 6.86337111, 4.595545125, 2.578130269, 11.4248793,
2.958851115, 2.340767158, 5.134842087, 2.837711812, 6.180169144,
4.445131477, 6.74644117), GSM239326 = c(2.922820483, 6.466679556,
4.747114589, 7.094488581, 2.18332885, 6.865970678, 4.575545289,
2.659717988, 10.74738082, 3.047880699, 2.32143889, 5.367342376,
2.859800224, 6.151689376, 4.51471011, 7.04995802), GSM239328 = c(3.15950317,
6.432795021, 4.830045513, 7.024332721, 2.12778313, 7.219840938,
4.547957809, 2.567436676, 9.296043108, 2.878562717, 2.282608342,
5.682051149, 2.866040813, 6.238949956, 4.491645167, 6.938928532
), GSM239329 = c(3.163327169, 6.407321524, 4.213762092, 7.17928981,
2.269697813, 7.181113053, 4.68215122, 2.8095128, 9.53150669,
3.209319974, 2.401218719, 5.712072512, 2.969167906, 6.708196123,
4.460114204, 6.348253102), GSM239331 = c(2.985901308, 6.426470803,
4.884418365, 7.159898654, 2.264705552, 7.392230178, 4.674495889,
2.790110381, 8.285160496, 3.20260379, 2.385568421, 5.57179966,
2.929449968, 6.441437631, 4.602482637, 6.080950712), GSM239332 = c(3.122708843,
6.376394357, 4.4318876, 7.009977785, 2.253940441, 7.484052914,
4.675841709, 2.795882913, 9.769919327, 3.195993624, 2.375334953,
5.72082395, 2.963530689, 6.448280595, 4.587221948, 6.324619355
), GSM239333 = c(3.070948463, 6.469070308, 4.849665444, 6.830979234,
2.287924323, 7.52498281, 4.643311767, 2.884588792, 9.774610531,
3.3004227, 2.432634747, 5.656674512, 2.931065261, 6.413562269,
4.623125028, 6.472893789)), class = "data.frame", row.names = c(NA, -16L))
CodePudding user response:
You can achieve this by pivoting your data, recoding in a new variable and ploting. I'm doing this example with the tidyverse collection of packages (tidyr, dplyr, ggplot2, etc).
First we load the packages and I'm creating a temporal dataset for this example. You can apply this to your own data.
Let's say I have a dataset with four columns.
library(tidyverse)
tmp <- data.frame(col1 = runif(10),
col2 = runif(10),
col3 = runif(10),
col4 = runif(10))
tmp
#> col1 col2 col3 col4
#> 1 0.90734014 0.5982927 0.8737742 0.4736948
#> 2 0.86152607 0.6449016 0.8081259 0.4717687
#> 3 0.82432693 0.1984189 0.8673977 0.2029126
#> 4 0.85152294 0.2304586 0.6021387 0.3914528
#> 5 0.38723829 0.5963829 0.6431011 0.8964814
#> 6 0.45445156 0.2750627 0.8670836 0.3399746
#> 7 0.38512391 0.5757645 0.9060044 0.1580425
#> 8 0.58636619 0.4287894 0.7827405 0.6647625
#> 9 0.50576266 0.6141626 0.5411717 0.4168770
#> 10 0.06328743 0.1455354 0.7490322 0.9065379
I know col1 and col2 are control groups, soy I need to pivot all my columns and create a type column to identify the control and treatment group. I've previously created the control_cols vector to have cleaner code. I think if you are new to R, the quickest way is to specify the 32 names manually. If you happen to know about regular expressions you can take advantage of that by using str_detect() in the colnames column.
control_cols <- c("col1", "col2")
tmp_transformed <- tmp %>%
pivot_longer(everything(), names_to = "colname", values_to = "value") %>%
mutate(type = if_else(colname %in% control_cols, "control", "treatment"))
tmp_transformed
#> # A tibble: 40 x 3
#> colname value type
#> <chr> <dbl> <chr>
#> 1 col1 0.907 control
#> 2 col2 0.598 control
#> 3 col3 0.874 treatment
#> 4 col4 0.474 treatment
#> 5 col1 0.862 control
#> 6 col2 0.645 control
#> 7 col3 0.808 treatment
#> 8 col4 0.472 treatment
#> 9 col1 0.824 control
#> 10 col2 0.198 control
#> # ... with 30 more rows
Once my data is ready i can now create a boxplot where each fill color is mapped to a group type. You can specify the colors manually inside scale_fill_manual().
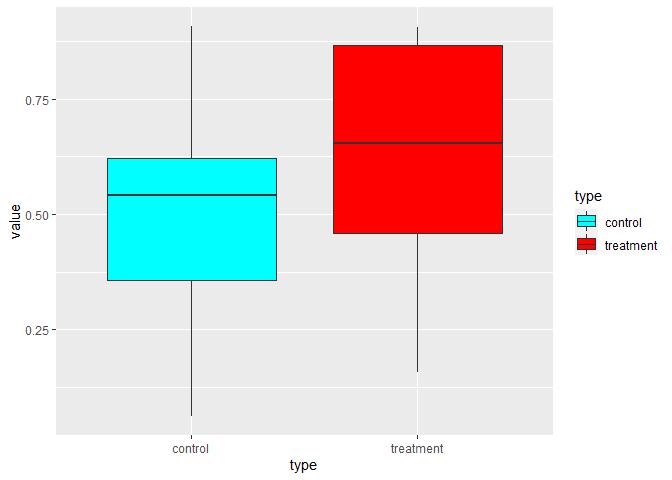
For control vs treatment:
tmp_transformed %>%
ggplot(aes(type, value, fill = type))
geom_boxplot()
scale_fill_manual(values = c("cyan", "red"))
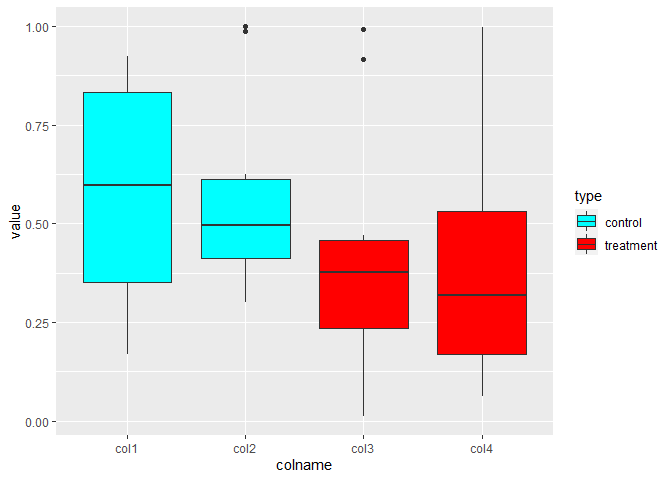
For colname and type
tmp_transformed %>%
ggplot(aes(colname, value, fill = type))
geom_boxplot()
scale_fill_manual(values = c("cyan", "red"))
Created on 2022-01-20 by the reprex package (v2.0.1)