I am looking for the data structure/algorithm, which could help me to solve the following task:
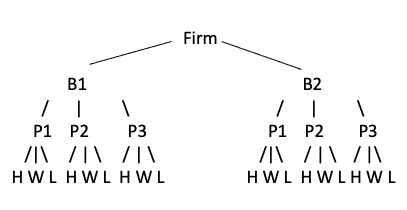
- imagine we have two business lines B1 and B2
- each business line has 3 products P1, P2, P3
- each product has same nomenclature of parameters, which my programme eventually will compute: H, W, L
To answer the comment: the values for H, W, L are indeed numbers.
To clarify further: all B, P and H,W,L are strings, but the values of H,W,L (I didn't show them on the tree) are numbers and all different.
In the first run, I was thinking about building a tree like this:
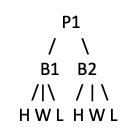
Then, I would like to perform an analytics, on let's say P1, so I need to be able to easily retrieve data from P1 node, across the tree like this:
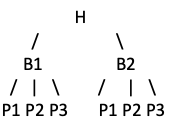
Subsequently, analytics on H would require retrieving data like this:
(For inspiration, this is quite easily achieved in Excel pivots, by just rearranging columns)
My language is Python and so far I came up only with nested dictionaries (though it's very tedious to search for nested keys), or dictionary with B1, B2 as keys and let's say (P1, H, value_of_H) as tuples, where I can see for each key if either P or H/W/L is in tuple.
CodePudding user response:
You could create a Pandas DataFrame with multiple index levels, and query it using xs:
import pandas as pd
import numpy as np
firms = ["B1", "B2"]
products = ["P1", "P2", "P3"]
params = ["H", "W", "L"]
df = pd.DataFrame(
index=pd.MultiIndex.from_product([firms, products, params]),
data=np.random.randint(1, 10, 2 * 3 * 3),
columns=["Value"]
)
# analytics on P1:
print(df.xs("P1", level=1))
# Value
# B1 H 5
# W 6
# L 9
# B2 H 1
# W 5
# L 7
# analytics on H:
print(df.xs("H", level=2))
# Value
# B1 P1 7
# P2 2
# P3 6
# B2 P1 5
# P2 6
# P3 6