I have 100k records in a dataframe
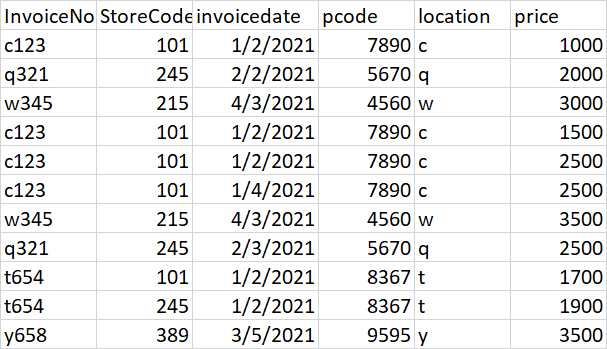
and want to find out different prices for the same product for the same invoice and different invoices along with the store. data snippet of the data mentioned
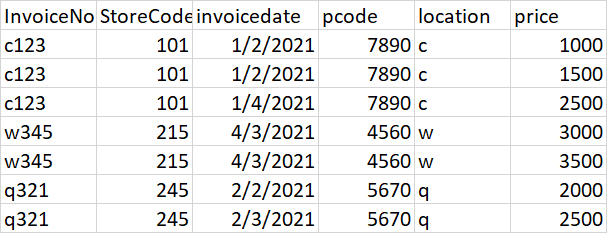
expected output
CodePudding user response:
It is not clear how to determine if products are the same, however you can use this code and change the subset values in order to keep only unique rows in the dataframe:
df = df.drop_duplicates(subset=['InvoiceCo', 'pcode', 'price'], keep="last").sort_values(by=['StoreCode'])
CodePudding user response:
You can use groupby to group a dataframe by multiple columns.
Let's create your DataFrame first:
import pandas as pd
InvoiceNo = pd.Series(data=["c123","q321","w345", "c123", "c123", "c123", "w345", "q321", "t654", "t654", "t658"])
StoreCode = pd.Series(data=[101,245,215,101,101,101,215,245,101,245,389])
price = pd.Series(data=[1000,2000,3000,1500,2500,2500,3500,2500,1700,1900,3500])
pcode = pd.Series(data=[7890,5670,4560,7890,7890,7890,4560,
5670,8367,8367,9595])
InvoiceNo.name = 'InvoiceNo'
StoreCode.name= 'StoreCode'
price.name= 'price'
pcode.name="pcode"
df = pd.concat([pd.DataFrame(InvoiceNo),pd.DataFrame(StoreCode),pd.DataFrame(price),pd.DataFrame(pcode)], axis=1)
Mask for the criteria (although this is not necessary for the example snippet given)
mask_invoice = df['InvoiceNo'].duplicated(keep=False)
mask_store = df["StoreCode"].duplicated(keep=False)
mask_pcode = df["pcode"].duplicated(keep=False)
df_masked = df[mask_pcode & mask_store & mask_invoice]
Now we have dropped the single entries by pcode, StoreCode and InvoiceNo.
InvoiceNo StoreCode price pcode
0 c123 101 1000 7890
1 q321 245 2000 5670
2 w345 215 3000 4560
3 c123 101 1500 7890
4 c123 101 2500 7890
5 c123 101 2500 7890
6 w345 215 3500 4560
7 q321 245 2500 5670
8 t654 101 1700 8367
9 t654 245 1900 8367
Grouping the dataframe with multiple columns:
dfg = df_masked.groupby(by=["StoreCode", "InvoiceNo"])
df_output = pd.DataFrame()
for group, data in dfg:
data.drop_duplicates(subset=["InvoiceNo", "StoreCode", "price"] ,inplace=True, ignore_index=True)
if len(data) >1:
df_output = pd.concat([df_output, data], ignore_index=True)
data.drop_duplicates eliminates duplicate rows within the grouped data - "c123" with price 2500 in this case.
Final output:
print(df_output)
>> InvoiceNo StoreCode price pcode
0 c123 101 1000 7890
1 c123 101 1500 7890
2 c123 101 2500 7890
3 w345 215 3000 4560
4 w345 215 3500 4560
5 q321 245 2000 5670
6 q321 245 2500 5670