Currently trying to run a very basic linear regression using some test data points on a jupyter notebook. below is my code, and as you can see if you run this the prediction line certainly moves towards where it should go but then it stops for some reason and I'm not really sure why. Can anyone help me?
starting weights
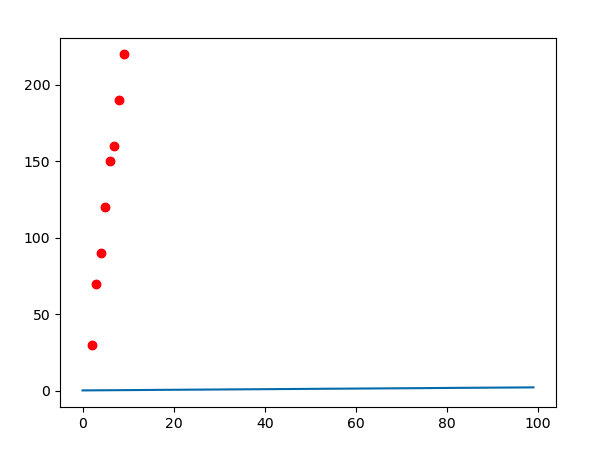
ending weights
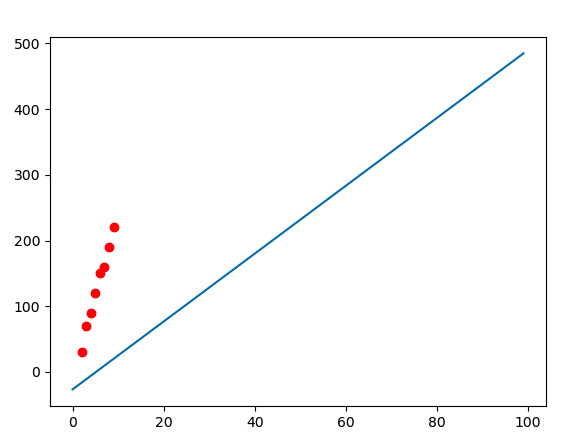
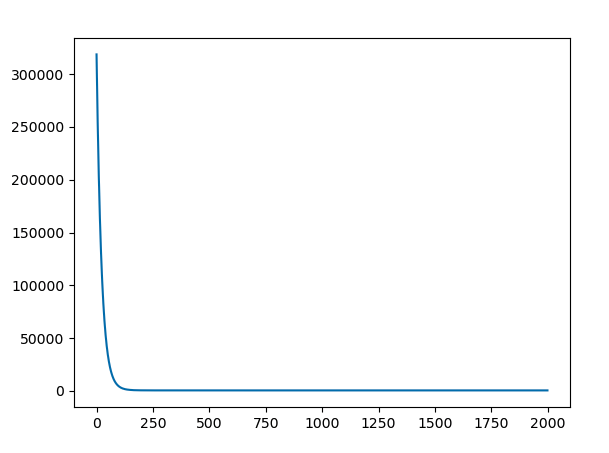
Loss
import matplotlib.pyplot as plt
import numpy as np
%matplotlib notebook
plt.style = "ggplot"
y = np.array([30,70,90,120,150,160,190,220])
x = np.arange(2,len(y) 2)
N = len(y)
weights = np.array([0.2,0.2])
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(y_hat)
x_ticks = np.array([[1,x*0.1] for x in range(100)])
y_hat = []
for j in range(len(x_ticks)):
y_hat.append(np.dot(weights, x_ticks[j]))
def plot_model(x, y, weights, loss):
x_ticks = np.array([[1,x*0.1] for x in range(100)])
y_hat = []
for j in range(len(x_ticks)):
y_hat.append(np.dot(weights, x_ticks[j]))
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(y_hat)
plt.figure()
plt.plot(loss)
def calculate_grad(weights, N, x_proc, y, loss):
residuals = np.sum(y.reshape(N,1) - weights*x_proc, 1)
loss.append(sum(residuals**2)/2)
#print(residuals, x_proc)
return -np.dot(residuals, x_proc)
def adjust_weights(weights, grad, learning_rate):
weights -= learning_rate*grad
return weights
learning_rate = 0.006
epochs = 2000
loss = []
x_processed = np.array([[1,i] for i in x])
for j in range(epochs):
grad = calculate_grad(weights, N, x_processed, y, loss)
weights = adjust_weights(weights, grad, learning_rate)
if j % 200 == 0:
print(weights, grad)
plot_model(x, y, weights, loss)
CodePudding user response:
There are a couple of problems.
First let's talk about the manner in which you are trying to find your parameters. You have some issues with the way you're doing your matrix and vector multiplications. I like to visualize the weights AND y as a column vector.
Then, you'll know that we need to take the dot product of your processed x matrix and weights column vector. That's step 1.
Now, remember your chain rule! You were on the right track with your gradient, but you need to remember to multiply x_proc * residuals by (-2/n) where n is the number of observations you have!
Here's that code:
y = np.array([[30,70,90,120,150,160,190,220]]).T
x = np.arange(2,len(y) 2)
N = len(y)
weights = np.array([0.2,0.2])
def calculate_grad(weights, N, x_proc, y, loss):
y_hat = np.dot(x_proc, weights.reshape(2,1))
residuals = y - y_hat
gradient = (-2/float(len(x_proc)))*sum(x_proc * residuals)
return gradient
def adjust_weights(weights, grad, learning_rate):
weights -= learning_rate*grad
return weights
Now for the plotting issue.
There's no need to increment by 0.1 on the x. You should simply use x_proc as you did when finding your weights. Like so:
def plot_model(x, y, weights, loss):
y_hat = []
for j in x:
y_hat.append(np.dot(weights, [1, j]))
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(x, y_hat)
plt.show()
And tada, with 2000 iterations you get weights: [-12.80036278 25.75042317] which is so close to the actual solution: [-13.33333 25.833333].
Here's working code:
import numpy as np
import matplotlib.pyplot as plt
y = np.array([[30,70,90,120,150,160,190,220]]).T
x = np.arange(2,len(y) 2)
N = len(y)
weights = np.array([0.2,0.2])
def plot_model(x, y, weights, loss):
y_hat = []
for j in x:
y_hat.append(np.dot(weights, [1, j]))
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(x, y_hat)
plt.show()
def calculate_grad(weights, N, x_proc, y, loss):
y_hat = np.dot(x_proc, weights.reshape(2,1))
residuals = y - y_hat
gradient = (-2/float(len(x_proc)))*sum(x_proc * residuals)
return gradient
def adjust_weights(weights, grad, learning_rate):
weights -= learning_rate*grad
return weights
learning_rate = 0.006
epochs = 2000
loss = []
x_processed = np.array([[1,i] for i in x])
for j in range(epochs):
grad = calculate_grad(weights, N, x_processed, y, loss)
weights = adjust_weights(weights, grad, learning_rate)
plot_model(x, y, weights, loss)
I think it would be helpful for me to explain to you how I solved this.
I started on pen and paper. It's not so important to find numerical values, but you must understand the order of operations (for example, multiplying the matrix x by a column vector of weights and not vice versa). Your code confused me because I was unsure of the mental map you had built for your order of operations.
Then from there, writing the code is easy.
If you want to check whether your solution is right, you can use the closed form solution (if there is one ;) ) to the least squares problem: inverse(X.TX)(X.T*y). In your case:
y = np.array([[30,70,90,120,150,160,190,220]]).T
x = np.arange(2,len(y) 2)
x = np.matrix([[1, x] for x in x])
beta_pt1 = np.linalg.inv(x.T*x)
beta_pt2 = x.T*y
beta = beta_pt1*beta_pt2
print(beta_pt1*beta_pt2)