I need to know how much it rained during a specific period of time using categorical variables and conditions. My real dataframe is 150 plus rows with much more variability in the "binned" or datetime column compared to the example dataframe I provided. I am looking for a for loop or function to grab the sum of precipitation (e.g. “TotalRain”) based on specific and variable intervals or periods of time that are based on certain conditions of the column “position.” This column "position" has blank rows, rows with "Start", or rows with "End". My idea is to create intervals/groups in the column “Groups” to better identify these intervals/groups, and then use these groups or another for loop to sum and then paste that sum of precipitation during that interval into the column “GroupRain.”
Here is an example dataset to use with the columns “Groups” and “GroupRain” provided for filling in:
dat<-data.frame(binned=as.POSIXct(c("2020-08-01 06:26:00", "2020-08-01 19:26:00", "2020-08-02 06:26:00", "2020-08-02 19:26:00", "2020-08-03 06:26:00","2020-08-03 19:26:00", "2020-08-04 06:26:00", "2020-08-04 19:26:00", "2020-08-05 06:26:00", "2020-08-05 19:26:00", "2020-08-06 06:26:00", "2020-08-06 19:26:00", "2020-08-07 06:26:00", "2020-08-07 19:26:00", "2020-08-08 06:26:00", "2020-08-08 19:26:00", "2020-08-09 06:26:00", "2020-08-09 19:26:00", "2020-08-10 06:26:00"), tz="America/Chicago"), position=c("","", "", "", "", "Start", "", "", "", "End", "", "", "", "Start", "End", "", "" ,"", "" ), TotalRain= as.numeric(c("0.0", "0.0", "0.1", "0.0", "0.0", "0.0", "0.2", "0.3", "0.0", "0.1", "0.0", "0.3", "0.0", "0.1", "0.0", "0.0", "0.4", "0.0", "0.0")), Groups=as.character(""), GroupRain=as.numeric(""))
Here is an image of the dataframe provided in the above code:
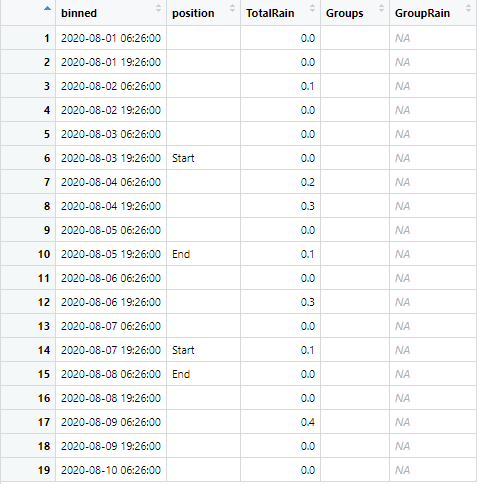
The issue I am having is creating a for loop or function that starts summing the “TotalRain” rows until a condition occurs or while a condition is occurring. For instance, the first 5 rows of my dataframe will be my first interval/group, and I want the sum of “Total Rain” to stop summing when the “position” column equals “Start”, then to paste this total in the “GroupRain” column where this first interval ends (e.g. row 5). The first “Start” in this dataframe will be the start of my 2nd interval/group that is also 5 rows long. For this second interval/group, I want to again grab the sum of “Total Rain” but stop when “position” equals “End” and paste the sum in this row. The third interval begins when position stops equaling “End” and is blank (e.g. row 11 to row 13), and goes until position equals “Start” again (e.g. row 14), and will have its sum pasted in row 13. The 4th interval/group is 2 rows long, or rows 14 and 15, and will have its sum pasted in row 15. And the 5th and final interval/group is 4 rows long, or rows 16 to 19, and will have its sum pasted in row 19. Below I have an example of an output dataframe where I manually created 5 interval/groups using the alphabet and manually summed and pasted the “Total Rain” for each interval into the “GroupRain” column. I am fine using the "LETTERS" package in R to provide my interval/group names (A, B, C, etc). The dataframe I want to end up with is provided below:
dat2<-data.frame(binned=as.POSIXct(c("2020-08-01 06:26:00", "2020-08-01 19:26:00", "2020-08-02 06:26:00", "2020-08-02 19:26:00", "2020-08-03 06:26:00","2020-08-03 19:26:00", "2020-08-04 06:26:00", "2020-08-04 19:26:00", "2020-08-05 06:26:00", "2020-08-05 19:26:00", "2020-08-06 06:26:00", "2020-08-06 19:26:00", "2020-08-07 06:26:00", "2020-08-07 19:26:00", "2020-08-08 06:26:00", "2020-08-08 19:26:00", "2020-08-09 06:26:00", "2020-08-09 19:26:00", "2020-08-10 06:26:00"), tz="America/Chicago"), position=c("","", "", "", "", "Start", "", "", "", "End", "", "", "", "Start", "End", "", "" ,"", "" ), TotalRain= as.numeric(c("0.0", "0.0", "0.1", "0.0", "0.0", "0.0", "0.2", "0.3", "0.0", "0.1", "0.0", "0.3", "0.0", "0.1", "0.0", "0.0", "0.4", "0.0", "0.0")), Groups=c("A", "A", "A", "A", "A", "B", "B", "B", "B", "B", "C", "C", "C", "D", "D", "E", "E", "E", "E"), GroupRain=as.numeric(c("", "", "", "", "0.1", "", "", "", "", "0.6", "0.0", "", "0.3", "", "0.1", "", "", "", "0.4")))
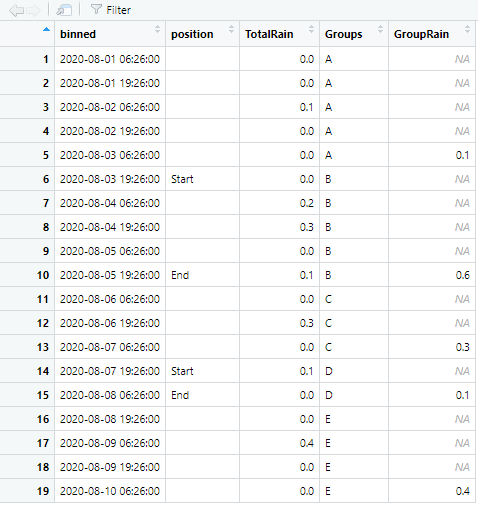
Group A or my first interval had a total of 0.1 inches. Group B or my 2nd interval had a total of 0.6 inches. Group C had a total of 0.3 inches. Group D had a total of 0.1 inches. And Group E had a total of 0.4 inches.
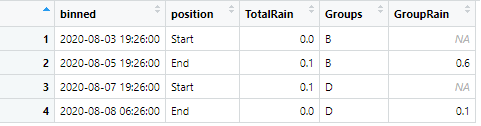
My end goal is to be able to filter the dataframe without losing all of the inbetween numeric data that I need to keep (like rain). When I filter based on “Start” and “End” position, I want to already have the summarized “TotalRain” column shown as “GroupRain” within that interval. For example, my final code will be this, which produces the following image and shows me that interval/group B had a total of 0.6 inches of rain. Interval/group D had a total of 0.1 inches of rain.
dat3<- dat2 %>%filter(position == "Start"|position == "End")
CodePudding user response:
base R
dat$ends <- rev(cumsum(rev(dat$position == "End")))
dat$withstarts <- with(dat, ave(position, ends, FUN = function(z) cumsum(z == "Start")))
dat$GroupRain <- with(dat, ave(TotalRain, list(ends, withstarts), FUN = function(z) c(rep(NA, length(z)-1), sum(z)), drop=TRUE))
with(dat, ave(position, list(ends, withstarts), FUN = function(z) !all(c("Start","End") %in% z)))
# [1] "TRUE" "TRUE" "TRUE" "TRUE" "TRUE" "FALSE" "FALSE" "FALSE" "FALSE" "FALSE" "TRUE"
# [12] "TRUE" "TRUE" "FALSE" "FALSE" "TRUE" "TRUE" "TRUE" "TRUE"
dat$GroupRain[with(dat, ave(position, list(ends, withstarts), FUN = function(z) !all(c("Start","End") %in% z))) == "TRUE"] <- NA
dat[c("ends","withstarts")] <- NULL
dat
# binned position TotalRain Groups GroupRain
# 1 2020-08-01 06:26:00 0.0 NA
# 2 2020-08-01 19:26:00 0.0 NA
# 3 2020-08-02 06:26:00 0.1 NA
# 4 2020-08-02 19:26:00 0.0 NA
# 5 2020-08-03 06:26:00 0.0 NA
# 6 2020-08-03 19:26:00 Start 0.0 NA
# 7 2020-08-04 06:26:00 0.2 NA
# 8 2020-08-04 19:26:00 0.3 NA
# 9 2020-08-05 06:26:00 0.0 NA
# 10 2020-08-05 19:26:00 End 0.1 0.6
# 11 2020-08-06 06:26:00 0.0 NA
# 12 2020-08-06 19:26:00 0.3 NA
# 13 2020-08-07 06:26:00 0.0 NA
# 14 2020-08-07 19:26:00 Start 0.1 NA
# 15 2020-08-08 06:26:00 End 0.0 0.1
# 16 2020-08-08 19:26:00 0.0 NA
# 17 2020-08-09 06:26:00 0.4 NA
# 18 2020-08-09 19:26:00 0.0 NA
# 19 2020-08-10 06:26:00 0.0 NA
Alternatively, after ends and withstarts have been added (above):
res <- aggregate(TotalRain ~ ends withstarts, data = dat, FUN = sum)
names(res)[3] <- "GroupRain"
dat2 <- merge(dat, res, by = c("ends", "withstarts"))
dat2$GroupRain[dat2$position != "End"] <- NA
dat2[,c("ends","withstarts")] <- NULL
dat2
# binned position TotalRain Groups GroupRain
# 1 2020-08-08 19:26:00 0.0 NA
# 2 2020-08-09 06:26:00 0.4 NA
# 3 2020-08-09 19:26:00 0.0 NA
# 4 2020-08-10 06:26:00 0.0 NA
# 5 2020-08-06 06:26:00 0.0 NA
# 6 2020-08-06 19:26:00 0.3 NA
# 7 2020-08-07 06:26:00 0.0 NA
# 8 2020-08-07 19:26:00 Start 0.1 NA
# 9 2020-08-08 06:26:00 End 0.0 0.1
# 10 2020-08-01 06:26:00 0.0 NA
# 11 2020-08-01 19:26:00 0.0 NA
# 12 2020-08-02 06:26:00 0.1 NA
# 13 2020-08-02 19:26:00 0.0 NA
# 14 2020-08-03 06:26:00 0.0 NA
# 15 2020-08-03 19:26:00 Start 0.0 NA
# 16 2020-08-04 06:26:00 0.2 NA
# 17 2020-08-04 19:26:00 0.3 NA
# 18 2020-08-05 06:26:00 0.0 NA
# 19 2020-08-05 19:26:00 End 0.1 0.6
dplyr
library(dplyr)
dat %>%
group_by(ends = rev(cumsum(rev(position == "End")))) %>%
group_by(withstarts = cumsum(position == "Start"), add = TRUE) %>%
mutate(GroupRain = if_else(all(c("Start", "End") %in% position) & row_number() == n(), sum(TotalRain), NA_real_)) %>%
ungroup() %>%
select(-ends, -withstarts)
# # A tibble: 19 x 5
# binned position TotalRain Groups GroupRain
# <dttm> <chr> <dbl> <chr> <dbl>
# 1 2020-08-01 06:26:00 "" 0 "" NA
# 2 2020-08-01 19:26:00 "" 0 "" NA
# 3 2020-08-02 06:26:00 "" 0.1 "" NA
# 4 2020-08-02 19:26:00 "" 0 "" NA
# 5 2020-08-03 06:26:00 "" 0 "" NA
# 6 2020-08-03 19:26:00 "Start" 0 "" NA
# 7 2020-08-04 06:26:00 "" 0.2 "" NA
# 8 2020-08-04 19:26:00 "" 0.3 "" NA
# 9 2020-08-05 06:26:00 "" 0 "" NA
# 10 2020-08-05 19:26:00 "End" 0.1 "" 0.6
# 11 2020-08-06 06:26:00 "" 0 "" NA
# 12 2020-08-06 19:26:00 "" 0.3 "" NA
# 13 2020-08-07 06:26:00 "" 0 "" NA
# 14 2020-08-07 19:26:00 "Start" 0.1 "" NA
# 15 2020-08-08 06:26:00 "End" 0 "" 0.1
# 16 2020-08-08 19:26:00 "" 0 "" NA
# 17 2020-08-09 06:26:00 "" 0.4 "" NA
# 18 2020-08-09 19:26:00 "" 0 "" NA
# 19 2020-08-10 06:26:00 "" 0 "" NA
Data
dat <- structure(list(binned = structure(c(1596281160, 1596327960, 1596367560, 1596414360, 1596453960, 1596500760, 1596540360, 1596587160, 1596626760, 1596673560, 1596713160, 1596759960, 1596799560, 1596846360, 1596885960, 1596932760, 1596972360, 1597019160, 1597058760), class = c("POSIXct", "POSIXt"), tzone = "America/Chicago"), position = c("", "", "", "", "", "Start", "", "", "", "End", "", "", "", "Start", "End", "", "", "", ""), TotalRain = c(0, 0, 0.1, 0, 0, 0, 0.2, 0.3, 0, 0.1, 0, 0.3, 0, 0.1, 0, 0, 0.4, 0, 0), Groups = c("", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ""), GroupRain = c(NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_, NA_real_)), row.names = c(NA, -19L), class = "data.frame")