Let´s say I have this dataset with 3 variables. One of them student is a string with the "name" of students.
df = data.frame(quest = c(2,4,6), test = rep(c("math","science","arts"),3), student = c("0risk, student1, student3","student1","0risk, student2, student3")) %>% arrange(quest, test)
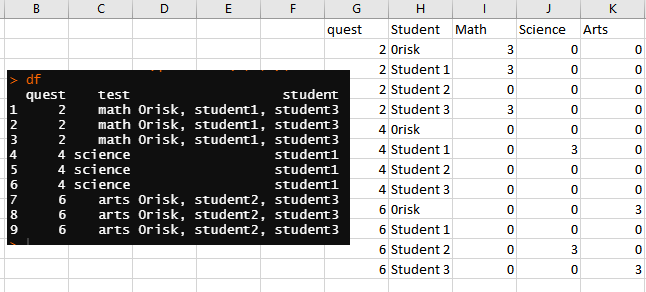
I would like to count students grouped by quest and test and return something like that
Any advice would be helpful. Thank you
CodePudding user response:
Using
tidyr::separate_rowsyou could split thestudentcolumn into rows,- get the counts using
dplyr::count, tidyr::completeyour dataset to get all combos of the categorical variables and- finally use
tidyr::pivot_widerto convert to wide format:
library(dplyr)
library(tidyr)
df %>%
tidyr::separate_rows(student) %>%
count(quest, test, student, .drop = FALSE) %>%
tidyr::complete(quest, test, student, fill = list(n = 0)) %>%
tidyr::pivot_wider(names_from = test, values_from = n, values_fill = 0)
#> # A tibble: 12 × 5
#> quest student arts math science
#> <dbl> <chr> <dbl> <dbl> <dbl>
#> 1 2 0risk 0 3 0
#> 2 2 student1 0 3 0
#> 3 2 student2 0 0 0
#> 4 2 student3 0 3 0
#> 5 4 0risk 0 0 0
#> 6 4 student1 0 0 3
#> 7 4 student2 0 0 0
#> 8 4 student3 0 0 0
#> 9 6 0risk 3 0 0
#> 10 6 student1 0 0 0
#> 11 6 student2 3 0 0
#> 12 6 student3 3 0 0