I have a dataframe,you can have it by running this code:
import numpy as np
import pandas as pd
from io import StringIO
df4s = """
LowerAge age 1 2 3 4
0 2 3 o.234 o.234 o.234 o.234
1 3 4 o.234 o.234 o.234 o.234
2 4 2 o.234 o.234 o.234 o.234
3 5 3 o.234 o.234 o.234 o.234
"""
df4 = pd.read_csv(StringIO(df4s.strip()), sep='\s ')
df4
The ouput is:
LowerAge age 1 2 3 4
0 2 3 o.234 o.234 o.234 o.234
1 3 4 o.234 o.234 o.234 o.234
2 4 2 o.234 o.234 o.234 o.234
3 5 3 o.234 o.234 o.234 o.234
Now the logic is like this: for each row ,if LowerAge-1 < age,then df4[str(LowerAge-1)] =1,or it will stay the same,for example:
In the first row,LowerAge-1 equals 1 and it is less than age,then value of column '1'(because LowerAge-1 equals 1) will equal 1,
in the second row, LowerAge-1 equals 2 and it is less than age, then value of column '2' will equal 1.
The final output should be:
LowerAge age '1' '2' '3' '4'
0 2 3 1 o.234 o.234 o.234
1 3 4 o.234 1 o.234 o.234
2 4 2 o.234 o.234 o.234 o.234
3 5 3 o.234 o.234 o.234 o.234
My code is:
lower_v=df4['LowerAge'].values - 1
df4[lower_v.astype(str)]=np.where(lower_v<df4['age'],1,df4[lower_v.astype(str)])
Error:
---> 19 df4[lower_v.astype(str)]=np.where(lower_v<df4['age'],1,df4[lower_v.astype(str)])
KeyError: "['1' '2' '3' '4'] not in index"
Any friend can hlep?
CodePudding user response:
Won't fix your code, but the current error is due to the fact your columns are '1' or '2' with quotes. Removing these quotes in the df definition got rid of this error, but your code didn't return the expected result either:
df4s = """
LowerAge age 1 2 3 4
0 2 3 o.234 o.234 o.234 o.234
1 3 4 o.234 o.234 o.234 o.234
2 4 2 o.234 o.234 o.234 o.234
3 5 3 o.234 o.234 o.234 o.234
"""
CodePudding user response:
I prefer to do slicing to solve this problem, so you can try this :
for i in range(len(df4)):
index_age = df4['LowerAge'].iloc[i]-1
if index_age<df4['age'].iloc[i]:
df4.iloc[i,index_age 1] = 1
And the result :
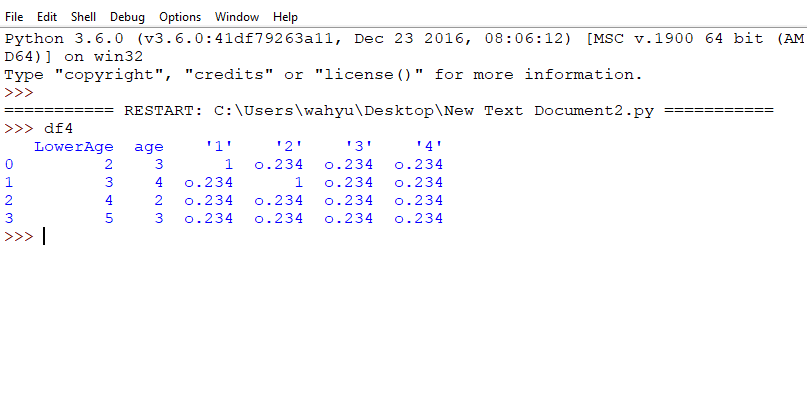
CodePudding user response:
you can do this :
def fun(x):
if x['LowerAge']-1<x['age']:
if x['LowerAge']-1<4:
x[str(x['LowerAge']-1)]=1
return x
df4.apply(fun,axis=1)
output:
LowerAge age '1' '2' '3' '4'
0 2 3 1 o.234 o.234 o.234
1 3 4 o.234 1 o.234 o.234
2 4 2 o.234 o.234 o.234 o.234
3 5 3 o.234 o.234 o.234 o.234
coming to time complexity linear complexity is must thing as we need to check for every row. There might be better solutions but this solution wont cost you much.