Lets say I have a dataframe below.
A B
a 1
a 2
a 3
b 1
b 2
b 3
c 1
c 2
c 3
d 1
I want to create dataframes with two columns: A : unique values in columns A and B: Possible values in column B for a given unique value in A. Note that all these dataframes must be unique. Example of few possible dataframes are given in the image below:
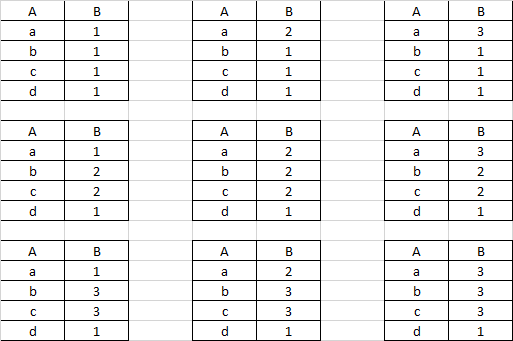
CodePudding user response:
The main idea is to group the values by column A, collecting values in B in lists, create a cartesian product of all these lists, and format back into a dataframe
First we load the data and groupby by column A, collecting all values in B into lists:
from io import StringIO
import pandas as pd
data = StringIO('''
A B
a 1
a 2
a 3
b 1
b 2
b 3
c 1
c 2
c 3
d 1
''')
df = pd.read_csv(data, sep = '\s ')
df2 = df.groupby('A').agg(list)
df2
df2 looks like this:
B
A
a [1, 2, 3]
b [1, 2, 3]
c [1, 2, 3]
d [1]
next we extract all lists in column B into a list of lists:
all_lists = df2['B'].to_list()
all_lists
it looks like this:
[[1, 2, 3], [1, 2, 3], [1, 2, 3], [1]]
Now the main step, create a product of the lists using MultiIndex.from_product functionality
mi = pd.MultiIndex.from_product(all_lists)
mi
mi looks like this:
MultiIndex([(1, 1, 1, 1),
(1, 1, 2, 1),
(1, 1, 3, 1),
(1, 2, 1, 1),
(1, 2, 2, 1),
(1, 2, 3, 1),
(1, 3, 1, 1),
(1, 3, 2, 1),
(1, 3, 3, 1),
(2, 1, 1, 1),
(2, 1, 2, 1),
(2, 1, 3, 1),
(2, 2, 1, 1),
(2, 2, 2, 1),
(2, 2, 3, 1),
(2, 3, 1, 1),
(2, 3, 2, 1),
(2, 3, 3, 1),
(3, 1, 1, 1),
(3, 1, 2, 1),
(3, 1, 3, 1),
(3, 2, 1, 1),
(3, 2, 2, 1),
(3, 2, 3, 1),
(3, 3, 1, 1),
(3, 3, 2, 1),
(3, 3, 3, 1)],
)
we are almost there -- now convert into a df and make sure we have the right label. Also remove duplicates (none in this case but in general a good idea)
(pd.DataFrame(index = mi)
.reset_index()
.drop_duplicates()
.set_axis(df2.index, axis=1)
.T
)
and we get a dataframe:
0 1 2 3 4 5 6 7 8 9 ... 17 18 19 20 21 22 23 24 25 26
A
a 1 1 1 1 1 1 1 1 1 2 ... 2 3 3 3 3 3 3 3 3 3
b 1 1 1 2 2 2 3 3 3 1 ... 3 1 1 1 2 2 2 3 3 3
c 1 2 3 1 2 3 1 2 3 1 ... 3 1 2 3 1 2 3 1 2 3
d 1 1 1 1 1 1 1 1 1 1 ... 1 1 1 1 1 1 1 1 1 1
where the index is the old column A and each column is a unique combination of relevant values from old column B
You can split it into separate dataframes if you need to, by looping over columns if you wish