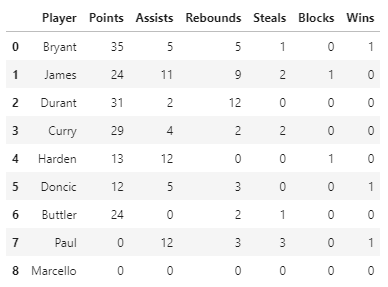
So I have a dataframe that looks like this:
| Player | Points | Assists | Rebounds | Steals | Blocks | Wins |
|---|---|---|---|---|---|---|
| Bryant | 35 | 5 | 5 | 1 | 0 | 1 |
| James | 24 | 11 | 9 | 2 | 1 | 0 |
| Durant | 31 | 2 | 12 | 0 | 0 | 0 |
| Curry | 29 | 4 | 2 | 2 | 0 | 0 |
| Harden | 13 | 12 | 0 | 0 | 1 | 0 |
| Doncic | 12 | 5 | 3 | 0 | 0 | 1 |
| Buttler | 24 | 0 | 2 | 1 | 0 | 0 |
| Paul | 0 | 12 | 3 | 3 | 0 | 1 |
And I want to take a random sample from that dataframe, but in a way that in the resulting sample, each column will have at least one value different from 0. So for example if I decide to take a random sample of 3 players, those 3 players can't be James, Durant and Curry since all three of them have zeros on the Win column. They also couldn't be Bryant, Doncic and Paul since they all have zero blocks.
How can I do this ?
FWI: This dataframe is just a simplification, mine has a lot more of rows and columns, hence I need a generic answer or method.
Thanks!
CodePudding user response:
Try this. I took myself the freedom to add a new player:
import pandas as pd
df = pd.read_csv('./data/players.csv')
_cols = list(df.columns)
_cols.remove('Player')
df['sum'] = df[_cols].sum(axis=1)
df
samples = 3
df[(df['sum']!=0)].sample(samples)
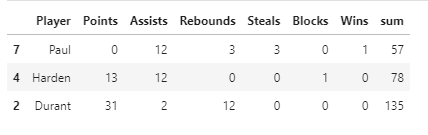
Unfortunately Marcello will never be sampled.
CodePudding user response:
IIUC, you can try something like this:
def sample_df(df, n=3):
while True:
dfs=df.sample(n)
#print(dfs) Just added this print to show dataframes dropped do to zeroes
if ~dfs.iloc[:,1:].sum().eq(0).any():
return dfs
sample_df(df)
Output:
Player Points Assists Rebounds Steals Blocks Wins
1 James 24 11 9 2 1 0
0 Bryant 35 5 5 1 0 1
2 Durant 31 2 12 0 0 0