I'm working on a pyspark routine to interpolate the missing values in a configuration table.
Imagine a table of configuration values that go from 0 to 50,000. The user specifies a few data points in between (say at 0, 50, 100, 500, 2000, 500000) and we interpolate the remainder. My solution mostly follows 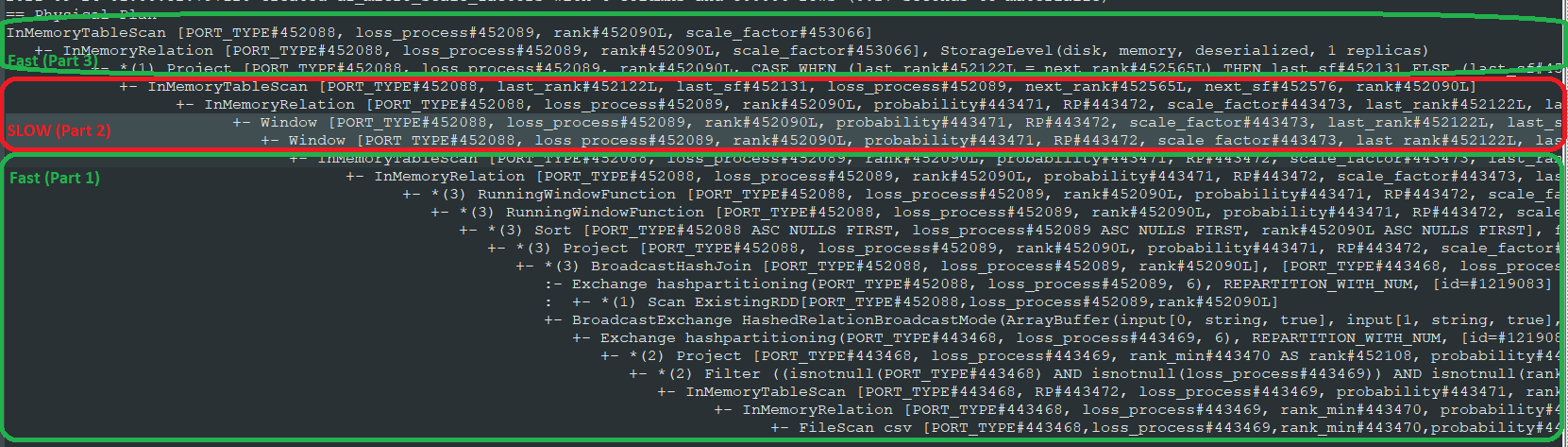
The only differences I can see is that:
- The first two calls (to
last) showRunningWindowFunction, whereas the calls tonextjust readWindow - Part 1 had a *(3) next to it, but Part 2 does not.
Some things I tried:
- I tried further splitting part 2 into separate dataframes - the result is that each
firststatement takes half of the total time (~98 seconds) - I tried reversing the order in which I generate these columns (e.g. placing the calls to 'last' after the calls to 'first') but there's no difference. Whichever dataframe ends up containing the calls to
firstis the slow one.
I feel like I've done as much digging as I can and am kind of hoping a spark expert will take one look at know where this time is coming from.
CodePudding user response:
The solution that doesn't answer the question
In trying various things to speed up my routine, it occurred to me to try re-rewriting my usages of first() to just be usages of last() with a reversed sort order.
So rewriting this:
win_next = (Window.partitionBy('PORT_TYPE', 'loss_process')
.orderBy('rank').rowsBetween(0, Window.unboundedFollowing))
df_part2 = (df_part1
.withColumn('next_rank', F.first(F.col('rank'), ignorenulls=True).over(win_next))
.withColumn('next_sf', F.first(F.col('scale_factor'), ignorenulls=True).over(win_next))
)
As this:
win_next = (Window.partitionBy('PORT_TYPE', 'loss_process')
.orderBy(F.desc('rank')).rowsBetween(Window.unboundedPreceding, 0))
df_part2 = (df_part1
.withColumn('next_rank', F.last(F.col('rank'), ignorenulls=True).over(win_next))
.withColumn('next_sf', F.last(F.col('scale_factor'), ignorenulls=True).over(win_next))
)
Much to my amazement, this actually solved the performance problem, and now the entire dataframe is generated in just 3 seconds. I'm pleased, but still vexed.
As I somewhat predicted, the query plan now includes a new SORT step before creating these next two columns, and they've changed from Window to RunningWindowFunction as the first two. Here's the new plan (without the code broken up into 3 separate cached parts anymore, because that was just to troubleshoot performance):
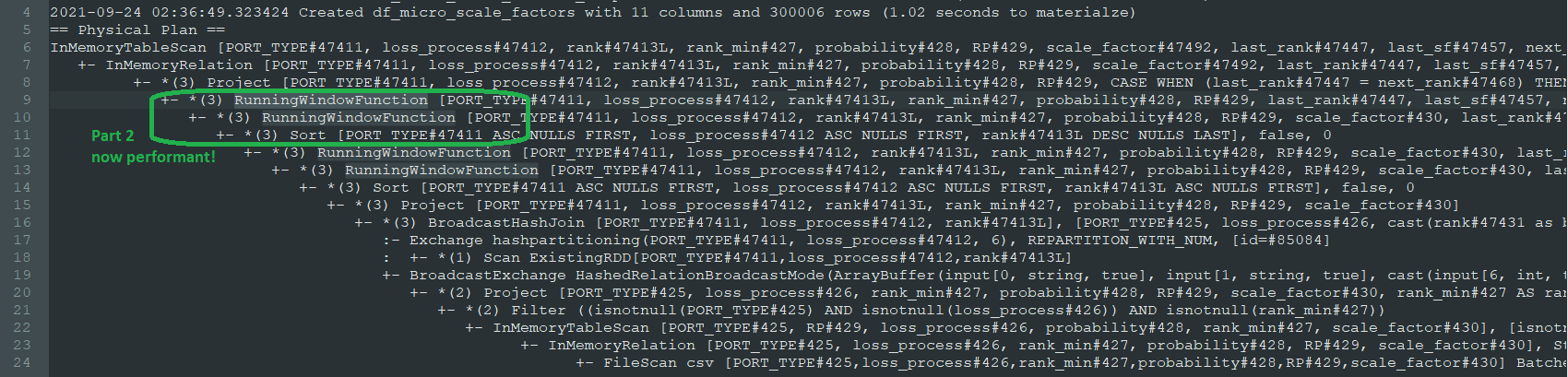
As for the question:
Why do my calls to first() over Window.unboundedFollowing take so much longer than last() over Window.unboundedPreceding?
I'm hoping someone can still answer this, for academic reasons